Objetivos didácticos
Al final de esta lección el estudiante podrá:
- Debatir sobre las ideas básicas de la regresión lineal y la correlación.
- Crear e interpretar la línea de mejor ajuste.
- Calcular e interpretar el coeficiente de correlación.
- Calcular e interpretar los valores atípicos.
Introducción
Los profesionales a menudo quieren saber cómo se relacionan dos o más variables numéricas. Por ejemplo, ¿existe una relación entre la calificación del segundo examen de Matemáticas que toma un estudiante y la calificación del examen final? Si hay una relación, ¿cuál es la relación y cuán fuerte es?
En otro ejemplo, puede que tus ingresos los determinen tu educación, tu profesión, tus años de experiencia y tu capacidad. La cantidad que se paga a un reparador por la mano de obra suele estar determinada por una cantidad inicial más una tarifa por hora.
Los datos que se describen en los ejemplos son bivariados: “bi” de dos variables. En realidad, los estadísticos utilizan datos multivariantes, es decir, muchas variables.
En este tema, se estudiará la forma más sencilla de regresión: la “regresión lineal” con una variable independiente (x). Se trata de datos que se ajustan a una línea en dos dimensiones. También estudiará la correlación, que mide la fuerza de la relación.

Contenidos temáticos
- Ecuaciones lineales
- Diagramas de dispersión
- La ecuación de regresión
- Comprobación de la importancia del coeficiente de correlación
- Predicción
- Valores atípicos
Desarrollo del tema
Ecuaciones lineales
La regresión lineal para dos variables se basa en una ecuación lineal con una variable independiente. La ecuación tiene la forma:
y = a + bx
donde a y b son números constantes.
La variable x es la variable independiente, y y es la variable dependiente. Normalmente, se elige un valor para sustituir la variable independiente y luego se resuelve la variable dependiente.
Ejemplo:
Los siguientes ejemplos son ecuaciones lineales.
y = 3 + 2x
y = − 0,01 + 1,2x
El gráfico de una ecuación lineal de la forma y = a + bx es una línea recta. Cualquier línea que no sea vertical puede ser descrita por esta ecuación.
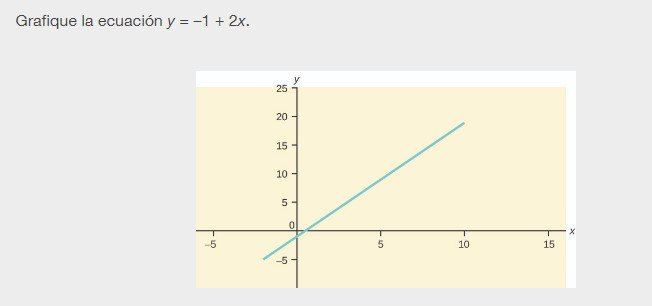
Pendiente e intersección en Y de una ecuación lineal
Para la ecuación lineal y = a + bx, b = pendiente y a = intersección en y. De Álgebra recuerde que la pendiente es un número que describe la inclinación de una línea, y la intersección en y es la coordenada y del punto (0, a) donde la línea cruza el eje y.
Diagramas de dispersión
Antes de retomar el análisis de la regresión lineal y la correlación, necesitamos examinar una forma de mostrar la relación entre dos variables de la x y de la y. La forma más común y sencilla es el diagrama de dispersión. El siguiente ejemplo ilustra un diagrama de dispersión.
Ejemplo:
En Europa y Asia, el comercio móvil es muy popular. Los usuarios del comercio móvil disponen de teléfonos móviles especiales que funcionan como monederos electrónicos y ofrecen servicios de telefonía e internet. Los usuarios pueden hacer de todo: desde pagar el estacionamiento hasta comprar un televisor o una gaseosa en una máquina, pasando por realizar operaciones bancarias o consultar los resultados deportivos en internet. En el periodo que va desde 2000 hasta 2004, ¿existe alguna relación entre el año y el número de usuarios de comercio móvil? Construya un diagrama de dispersión. Supongamos que la x = el año y la y = el número de usuarios de comercio móvil, en millones.
| x (año) | y (número de usuarios) |
|---|---|
| 2000 | 0,5 |
| 2002 | 20,0 |
| 2003 | 33,0 |
| 2004 | 47,0 |
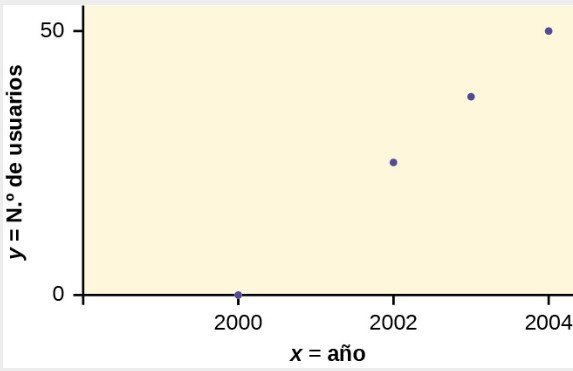
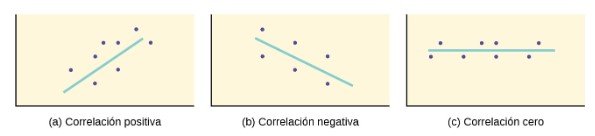
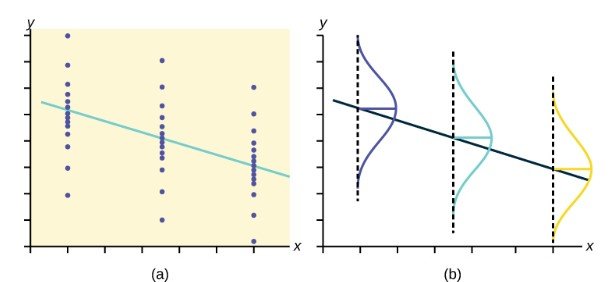
El diagrama de dispersión muestra la dirección de una relación entre las variables. Una dirección clara ocurre cuando hay:
- Valores altos de una variable que se producen con valores altos de la otra variable o valores bajos de una variable que se producen con valores bajos de la otra variable.
- Valores altos de una variable que se producen con valores bajos de la otra variable.
Puede determinar la fuerza de la relación al observar en diagrama de dispersión lo cerca que están los puntos de una línea, una función de potencia, una función exponencial o algún otro tipo de función. Para la relación lineal hay una excepción. Considere un diagrama de dispersión en el que todos los puntos caen sobre una línea horizontal que proporciona un “ajuste perfecto”. De hecho, la línea horizontal no mostraría ninguna relación.
Cuando se observa un diagrama de dispersión, hay que fijarse en el patrón general y en las desviaciones del patrón. Los siguientes ejemplos de diagramas de dispersión ilustran estos conceptos.
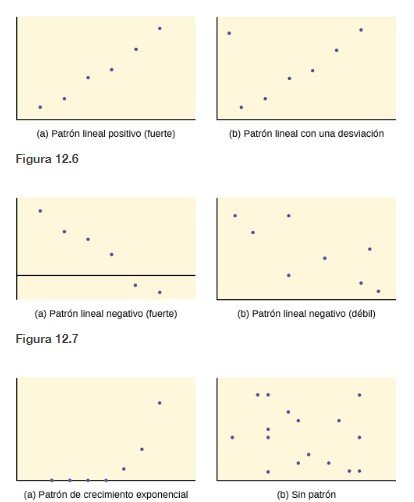
En este capítulo, nos interesan los diagramas de dispersión que muestran un patrón lineal. Los patrones lineales son bastante comunes. La relación lineal es fuerte si los puntos se acercan a una línea recta, excepto en el caso de una línea horizontal donde no hay relación. Si pensamos que los puntos muestran una relación lineal, nos gustaría dibujar una línea en el diagrama de dispersión. Esta línea se calcula mediante un proceso denominado regresión lineal. Sin embargo, solo calculamos una línea de regresión si una de las variables explica o predice la otra variable. Si la x es la variable independiente, mientras que la y es la variable dependiente, podemos utilizar una línea de regresión para predecir la y para un valor dado de la x.
La ecuación de regresión
Los datos rara vez se ajustan exactamente a una línea recta. Por lo general, hay que conformarse con predicciones aproximadas. Normalmente, se tiene un conjunto de datos cuyo diagrama de dispersión parece “ajustarse” a una línea recta. Esto se llama línea de mejor ajuste o línea de mínimos cuadrados.
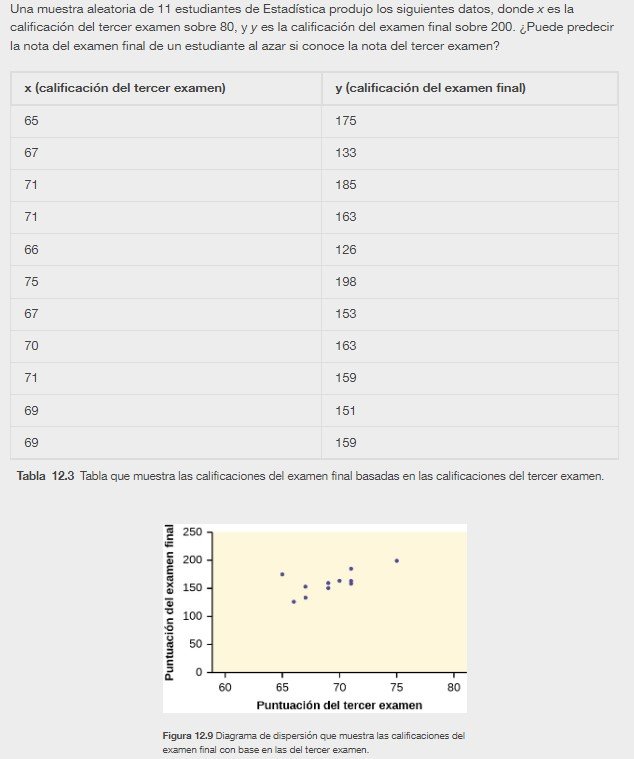
La puntuación del tercer examen, x, es la variable independiente y la puntuación del examen final, y, es la variable dependiente. Trazaremos la línea de regresión que mejor se “ajuste” a los datos. Si cada uno de ustedes ajustara una línea “a ojo”, trazarían líneas diferentes. Podemos utilizar lo que se llama una línea de regresión por mínimos cuadrados para obtener la línea de mejor ajuste.
Considere el siguiente diagrama. Cada punto de los datos tiene la forma (x, y) y cada punto de la línea de mejor ajuste utilizando la regresión lineal por mínimos cuadrados tiene la forma (x, ŷ).
La ŷ se lee “estimador de y“, a la vez que es el valor estimado de y. Es el valor de y obtenido mediante la línea de regresión. Generalmente no es igual a la y de los datos.
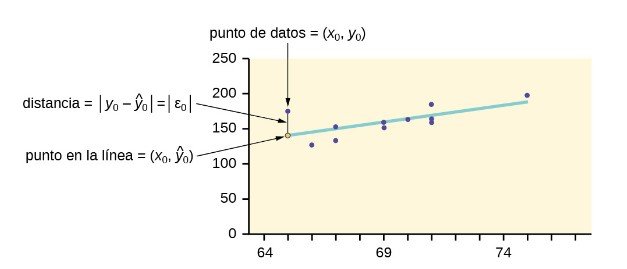
El término y0 – ŷ0 = ε0 se denomina “error” o residual. No es un error en el sentido de una equivocación. El valor absoluto del residual mide la distancia vertical entre el valor real de y, además del valor estimado de y. En otras palabras, mide la distancia vertical entre el punto de datos real y el punto previsto en la línea.
Si el punto de datos observado se encuentra por encima de la línea, el residuo es positivo y la línea subestima el valor real de los datos para y. Si el punto de datos observado se encuentra por debajo de la línea, el residuo es negativo y la línea sobreestima ese valor de datos real para y.
En el diagrama anterior, y0 – ŷ0 = ε0 es el residual del punto mostrado. Aquí el punto está por encima de la línea y el residuo es positivo.
ε = la letra griega épsilon
Para cada punto de datos, puede calcular los residuales o errores, yi – ŷi = εi para i = 1, 2, 3, …, 11.
Cada |ε| es una distancia vertical.
Para el ejemplo de las puntuaciones del tercer examen y del examen final de los 11 estudiantes de Estadística, hay 11 puntos de datos. Por lo tanto, hay 11 valores ε. Si se eleva al cuadrado cada ε y se suma, se obtiene:
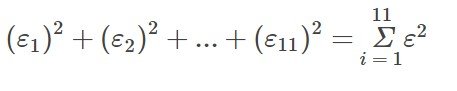
Esto se denomina suma de errores al cuadrado (Sum of Squared Errors, SSE).
Utilizando el cálculo, puede determinar los valores de a y b que hacen que la SSE sea un mínimo. Cuando hace la SSE un mínimo, ha determinado los puntos que están en la línea de mejor ajuste. Resulta que la línea de mejor ajuste tiene la ecuación:

Criterio de mínimos cuadrados para el mejor ajuste
El proceso de ajuste de la línea de mejor ajuste se denomina regresión lineal. La idea de hallar la línea de mejor ajuste se basa en la suposición de que los datos están dispersos alrededor de una línea recta. El criterio para la línea de mejor ajuste es que la suma de errores al cuadrado (SSE) se minimice, es decir, que sea lo más pequeña posible. Cualquier otra línea que se elija tendrá una SSE mayor que la línea de mejor ajuste. Esta línea de mejor ajuste se denomina línea de regresión por mínimos cuadrados.
EJEMPLO DEL TERCER EXAMEN versus el EXAMEN FINAL:
El gráfico de la línea de mejor ajuste para el ejemplo del tercer examen o examen final es el siguiente:
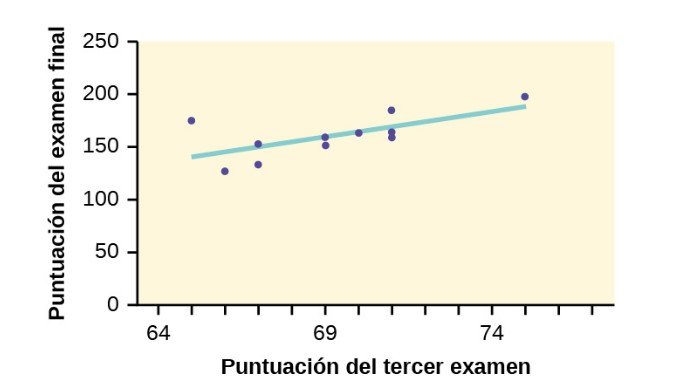
La línea de regresión de mínimos cuadrados (línea de mejor ajuste) para el ejemplo del tercer examen o examen final viene dada por la ecuación:
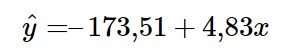
ENTENDER LA PENDIENTE: La pendiente de la línea, b, describe cómo se relacionan los cambios en las variables. Es importante interpretar la pendiente de la línea en el contexto de la situación representada por los datos. Debería ser capaz de escribir una frase interpretando la pendiente en inglés sencillo.
INTERPRETACIÓN DE LA PENDIENTE: La pendiente de la línea de mejor ajuste nos indica cómo cambia la variable dependiente (y) por cada incremento unitario de la variable independiente (x), en promedio.
EJEMPLO DEL TERCER EXAMEN versus el EXAMEN FINAL
- Pendiente: La pendiente de la línea es b = 4,83.
- Interpretación: Por un aumento de un punto en la puntuación del tercer examen, la puntuación del examen final aumenta en 4,83 puntos, en promedio.
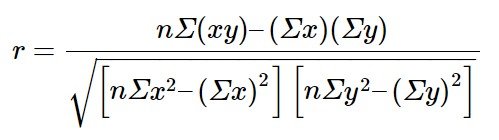
donde n = el número de puntos de datos.
Si se sospecha que existe una relación lineal entre x y y, entonces r puede medir la fuerza de la relación lineal.
Lo que nos dice el VALOR de r:
- El valor de r está siempre entre -1 y +1: -1 ≤ r ≤ 1.
- El tamaño de la correlación r indica la fuerza de la relación lineal entre x y y. Los valores de r cercanos a -1 o a +1 indican una relación lineal más fuerte entre x y y.
- Si r = 0 es probable que no haya correlación lineal. Sin embargo, es importante ver el diagrama de dispersión, porque los datos que muestran un patrón curvo u horizontal pueden tener una correlación de 0.
- Si r = 1, hay una correlación positiva perfecta. Si r = –1, hay una correlación negativa perfecta. En ambos casos, todos los puntos de datos originales se encuentran en una línea recta. Por supuesto, en el mundo real, esto no suele ocurrir.
Lo que nos dice el SIGNO de r
- Un valor positivo de r significa que cuando x aumenta, y tiende a aumentar y cuando x disminuye, y tiende a disminuir (correlación positiva).
- Un valor negativo de r significa que cuando x aumenta, y tiende a disminuir y cuando x disminuye, y tiende a aumentar (correlación negativa).
- El signo de r es el mismo que el de la pendiente, b, de la línea de mejor ajuste.
La fórmula de r parece formidable. Sin embargo, las hojas de cálculo, los softwares estadísticos y muchas calculadoras pueden calcular rápidamente r. El coeficiente de correlación r es el elemento inferior de las pantallas de salida de LinRegTTest en las calculadoras TI-83, TI-83+ o TI-84+ (vea la sección anterior para las instrucciones).
El coeficiente de determinación
La variable r2 se denomina el coeficiente de determinación y es el cuadrado del coeficiente de correlación, pero suele indicarse en porcentaje, en lugar de en forma decimal. Tiene una interpretación en el contexto de los datos:
- r2r2, cuando se expresa en porcentaje, representa el porcentaje de variación de la variable dependiente (predicha) y que puede explicarse por la variación de la variable independiente (explicativa) x utilizando la línea de regresión (de mejor ajuste).
- 1 – r2r2, cuando se expresa como porcentaje, representa el porcentaje de variación en y que NO se explica por la variación en x utilizando la línea de regresión. Esto puede verse como la dispersión de los puntos de datos observados en torno a la línea de regresión.
Considere el ejemplo del tercer examen o examen final introducido en la sección anterior
- La línea de mejor ajuste es: ŷ = -173,51 + 4,83x
- El coeficiente de correlación es r = 0,6631
- El coeficiente de determinación es r2 = 0,66312 = 0,4397
- Interpretación de r2 en el contexto de este ejemplo:
- Aproximadamente el 44 % de la variación (0,4397 es aproximadamente 0,44) en las notas del examen final puede explicarse por la variación en las notas del tercer examen, utilizando la línea de regresión de mejor ajuste.
- Por lo tanto, aproximadamente el 56 % de la variación (1 – 0,44 = 0,56) en las notas del examen final NO puede explicarse por la variación en las notas del tercer examen, utilizando la línea de regresión de mejor ajuste. (Esto se ve como la dispersión de los puntos alrededor de la línea).
Comprobación de la importancia del coeficiente de correlación
El coeficiente de correlación, r, nos indica la fuerza y la dirección de la relación lineal entre la x y la y. Sin embargo, la fiabilidad del modelo lineal también depende del número de puntos de datos observados en la muestra. Tenemos que observar tanto el valor del coeficiente de correlación r como el tamaño de la muestra n, conjuntamente.
Realizamos una prueba de hipótesis de la “significación del coeficiente de correlación” para decidir si la relación lineal en los datos de la muestra es lo suficientemente fuerte como para utilizarla para modelar la relación en la población.
Los datos de la muestra se utilizan para calcular r, el coeficiente de correlación de la muestra. Si tuviéramos los datos de toda la población, podríamos hallar el coeficiente de correlación de la población. Pero como solo tenemos datos de la muestra, no podemos calcular el coeficiente de correlación de la población. El coeficiente de correlación de la muestra, r, es nuestra estimación del coeficiente de correlación de la población desconocido.
- El símbolo del coeficiente de correlación de la población es ρ, la letra griega “rho”.
- ρ = coeficiente de correlación de la población (desconocido)
- r = coeficiente de correlación de la muestra (conocido; calculado a partir de los datos de la muestra)
La prueba de hipótesis nos permite decidir si el valor del coeficiente de correlación de la población ρ es “cercano a cero” o “significativamente diferente de cero”. Lo decidimos en función del coeficiente de correlación de la muestra r y del tamaño de la muestra n.
Si la prueba concluye que el coeficiente de correlación es significativamente diferente de cero, decimos que el coeficiente de correlación es “significativo”.
- Conclusión: Hay pruebas suficientes para concluir que existe una relación lineal significativa entre la x y la y porque el coeficiente de correlación es significativamente diferente de cero.
- Lo que significa la conclusión: Existe una relación lineal significativa entre la x y la y. Podemos utilizar la línea de regresión para modelar la relación lineal entre la x y la y en la población.
Si la prueba concluye que el coeficiente de correlación no es significativamente diferente de cero (está cerca de cero), decimos que el coeficiente de correlación es “no significativo”.
- Conclusión: “No hay pruebas suficientes para concluir que existe una relación lineal significativa entre la x y la y porque el coeficiente de correlación no es significativamente diferente de cero”.
- Lo que significa la conclusión: No existe una relación lineal significativa entre la x y la y. Por lo tanto, NO podemos utilizar la línea de regresión para modelar una relación lineal entre la x y la y en la población.
COMPROBACIÓN DE LA HIPÓTESIS
- Hipótesis nula: H0: ρ = 0
- Hipótesis alternativa: Ha: ρ ≠ 0
SIGNIFICADO DE LAS HIPÓTESIS EN PALABRAS:
- Hipótesis nula H0: El coeficiente de correlación de la población NO ES significativamente diferente de cero. NO HAY ninguna relación lineal significativa (correlación) entre la x y la y en la población.
- Hipótesis alternativa Ha: El coeficiente de correlación de la población ES significativamente DIFERENTE de cero. EXISTE UNA RELACIÓN LINEAL SIGNIFICATIVA (correlación) entre la x y la y en la población.
SACAR UNA CONCLUSIÓN:Hay dos métodos para tomar la decisión. Los dos métodos son equivalentes y dan el mismo resultado.
Método 1: Utilizar el valor p
| USO DE LAS CALCULADORAS TI-83, 83+, 84, 84+ Para calcular el valor p con la función LinRegTTEST: En la pantalla de entrada de LinRegTTEST, en la línea que pide β o ρ, resalte “≠ 0“ La pantalla de salida muestra el valor p en la línea que dice “p =”. (La mayoría de los softwares de estadística pueden calcular el valor p). |
Si el valor p es inferior al nivel de significación(α = 0,05):
- Decisión: rechazar la hipótesis nula.
- Conclusión: “Hay pruebas suficientes para concluir que existe una relación lineal significativa entre la x y la y porque el coeficiente de correlación es significativamente diferente de cero”.
Si el valor p NO es inferior al nivel de significación (α = 0,05)
- Decisión: NO RECHAZAR la hipótesis nula.
- Conclusión: “No hay pruebas suficientes para concluir que existe una relación lineal significativa entre la x y la y porque el coeficiente de correlación NO es significativamente diferente de cero”.
Notas de cálculo:
- Utilizará la tecnología para calcular el valor p. A continuación se describen los cálculos para estimar los estadísticos de prueba y el valor p:
- El valor p se calcula mediante una distribución t con n – 2 grados de libertad.
- La fórmula para el estadístico de prueba es t=rn–2√1–r2√t=rn–21–r2. El valor del estadístico de prueba, t, se muestra en la salida de la computadora o de la calculadora junto con el valor p. El estadístico de prueba t tiene el mismo signo que el coeficiente de correlación r.
- El valor p es el área combinada en ambas colas.
Otra manera de calcular el valor p (p) dado por LinRegTTest es el comando 2*tcdf(abs(t),10^99, n-2) en 2nd DISTR.
EJEMPLO DE TERCER EXAMEN vs. EXAMEN FINAL: método del valor p
- Considera el ejemplo del tercer examen/examen final.
- La línea de mejor ajuste es: ŷ = -173,51 + 4,83x con r = 0,6631 y hay n = 11 puntos de datos.
- ¿Se puede utilizar la línea de regresión para la predicción? Dada la puntuación del tercer examen (valor x), ¿podemos utilizar la línea para predecir la puntuación del examen final (valor y predicho)?
H0: ρ = 0
Ha: ρ ≠ 0
α = 0,05
- El valor p es de 0,026 (a partir de la prueba LinRegTT en su calculadora o del software).
- El valor p, 0,026, es inferior al nivel de significación de α = 0,05.
- Decisión: Rechazar la hipótesis nula H0
- Conclusión: Hay pruebas suficientes para concluir que existe una relación lineal significativa entre la nota del tercer examen (x) y la nota del examen final (y) porque el coeficiente de correlación es significativamente diferente de cero.
Como r es significativa y el diagrama de dispersión muestra una tendencia lineal, la línea de regresión se puede usar para predecir calificaciones del examen final.
MÉTODO 2: Utilizar una tabla de valores críticos para tomar una decisión.
Los valores críticos al 95 % de la tabla de coeficientes de correlación de la muestra pueden utilizarse para dar una buena idea de si el valor calculado de rr es significativo o no lo es. Compare r con el valor crítico apropiado de la tabla. Si r no está entre los valores críticos positivos y negativos, el coeficiente de correlación es significativo. Si r es significativo, entonces puede utilizar la línea para la predicción.
Ejemplo:
Suponga que ha calculado r = 0,801 utilizando n = 10 puntos de datos. df = n – 2 = 10 – 2 = 8. Los valores críticos asociados a df = 8 son -0,632 y + 0,632. Si r < valor crítico negativo o r > valor crítico positivo, entonces r es significativo. Como r = 0,801 y 0,801 > 0,632, r es significativo y la línea puede utilizarse para la predicción. Si ve este ejemplo en una línea numérica, le ayudará.

Supuestos para comprobar la significación del coeficiente de correlación
La comprobación de la significación del coeficiente de correlación requiere que se cumplan ciertos supuestos sobre los datos. La premisa de esta prueba es que los datos son una muestra de puntos observados tomados de una población mayor. No hemos examinado a toda la población porque no es posible ni factible hacerlo. Estamos examinando la muestra para sacar una conclusión sobre si la relación lineal que vemos entre x y y en los datos de la muestra proporciona una evidencia lo suficientemente contundente como para que podamos concluir que existe una relación lineal entre x y y en la población.
La ecuación de la línea de regresión que calculamos a partir de los datos de la muestra da la línea de mejor ajuste para nuestra muestra particular. Queremos utilizar esta línea de mejor ajuste para la muestra como una estimación de la línea de mejor ajuste para la población. Examinar el diagrama de dispersión y comprobar la importancia del coeficiente de correlación nos permite
Los supuestos en los que se basa la prueba de significación son:
- Existe una relación lineal en la población que modela el valor promedio de la y para valores variables de la x. En otras palabras, el valor esperado de la y para cada valor en particular se encuentra en una línea recta en la población. (No conocemos la ecuación para la línea en la población. Nuestra línea de regresión de la muestra es nuestra mejor estimación de esta línea en la población).
- Los valores de la y para cualquier valor en particular de la x se distribuyen normalmente alrededor de la línea. Esto implica que hay más valores de la y dispersos cerca de la línea que los que están más lejos. El supuesto (1) implica que estas distribuciones normales están centradas en la línea: las medias de estas distribuciones normales de los valores de la y se encuentran en la línea.
- Las desviaciones típicas de los valores de la y de la población en torno a la línea son iguales para cada valor de la x. En otras palabras, cada una de estas distribuciones normales de los valores de la y tiene la misma forma y dispersión sobre la línea.
- Los errores residuales son mutuamente independientes (sin patrón).
- Los datos proceden de una muestra aleatoria bien diseñada o de un experimento aleatorio.
Predicción
Examinamos el diagrama de dispersión y mostramos que el coeficiente de correlación es significativo. Hallamos la ecuación de la línea de mejor ajuste para la calificación del examen final como una función de la calificación del tercer examen. Ahora podemos utilizar la línea de regresión por mínimos cuadrados para la predicción.
Suponga que quiere estimar, o predecir, la calificación media del examen final de los estudiantes de Estadística que obtuvieron 73 en el tercer examen. Las calificaciones del examen (valores x) oscilan entre 65 y 75. Dado que 73 está entre los valores de x 65 y 75, sustituya x = 73 en la ecuación. Entonces:
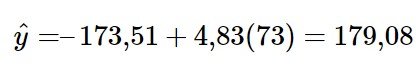
Predecimos que los estudiantes de Estadística que obtienen una calificación de 73 en el tercer examen obtendrán una calificación de 179,08 en el examen final, en promedio.
Valores atípicos
En algunos conjuntos de datos, hay valores (puntos de datos observados), llamados valores atípicos. Los valores atípicos son puntos de datos observados que se alejan de la línea de mínimos cuadrados. Tienen grandes “errores”, donde el “error” o residual es la distancia vertical de la línea al punto.
Los valores atípicos deben examinarse de cerca. A veces, por una u otra razón, no deben incluirse en el análisis de los datos. Es posible que un valor atípico sea el resultado de datos erróneos. Otras veces, un valor atípico puede contener información valiosa sobre la población estudiada y debe seguir incluyéndose en los datos. La clave está en examinar cuidadosamente las causas de que un punto de datos sea un valor atípico.
Además de los valores atípicos, una muestra puede contener uno o varios puntos que se denominan puntos influyentes. Se trata de puntos de datos observados que están alejados de los demás en la dirección horizontal. Estos puntos pueden tener un gran efecto en la pendiente de la línea de regresión. Para empezar a identificar un punto influyente, puede eliminarlo del conjunto de datos y ver si la pendiente de la línea de regresión cambia significativamente.
Se pueden utilizar computadoras y muchas calculadoras para identificar los valores atípicos de los datos. Los resultados de computadoras del análisis de regresión identifican tanto los valores atípicos como los puntos influyentes para que pueda examinarlos.
Identificar los valores atípicos
Podríamos adivinar los valores atípicos al observar un gráfico del diagrama de dispersión y la línea de mejor ajuste. Sin embargo, nos gustaría contar con alguna directriz sobre la distancia que debe tener un punto para considerarse un valor atípico. Como regla general, podemos señalar como valor atípico cualquier punto que esté situado más de dos desviaciones típicas por encima o por debajo de la línea de mejor ajuste. La desviación típica utilizada es la de los residuales o errores.
Podemos hacerlo visualmente en el diagrama de dispersión al dibujar un par de líneas adicionales que estén dos desviaciones típicas por encima y por debajo de la línea de mejor ajuste. Todos los puntos de datos que se encuentren fuera de este par de líneas adicionales se marcan como posibles valores atípicos. Alternativamente, podemos hacerlo numéricamente, al calcular cada residual y compararlo con el doble de la desviación típica. En la TI-83, 83+ u 84+, el enfoque gráfico es más fácil. En primer lugar se muestra el procedimiento gráfico, seguido de los cálculos numéricos. Por lo general, solo tendrá que utilizar uno de estos métodos.
Ejemplo:
En el ejemplo del tercer examen o examen final, se puede determinar si hay un valor atípico o no. Si hay un valor atípico, como ejercicio, elimínelo y ajuste los datos restantes a una nueva línea. En este ejemplo, la nueva línea debería ajustarse mejor a los datos restantes. Esto significa que el SSE debería ser menor y el coeficiente de correlación debería estar más cerca de 1 o –1.
Solución
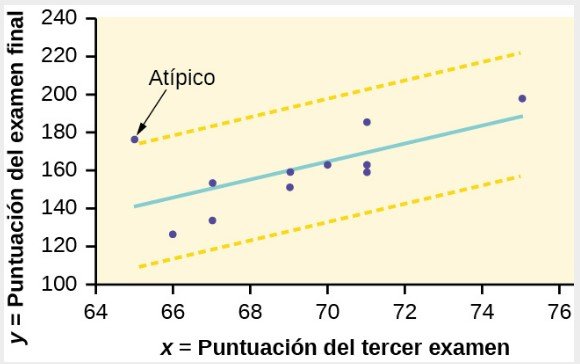
Identificación gráfica de los valores atípicos
Con las calculadoras gráficas TI-83, 83+ u 84+ es fácil identificar los valores atípicos de forma gráfica y visual. Si midiéramos la distancia vertical de cualquier punto de datos al punto correspondiente de la línea de mejor ajuste y esa distancia fuera igual a 2s o más, entonces consideraríamos que el punto de datos está “demasiado lejos” de la línea de mejor ajuste. Tenemos que calcular y graficar las líneas que están dos desviaciones típicas por debajo y por encima de la línea de regresión. Los puntos que estén fuera de estas dos líneas son valores atípicos. Llamaremos a estas líneas Y2 y Y3:
Al igual que hicimos con la ecuación de la línea de regresión y el coeficiente de correlación, utilizaremos la tecnología para calcular esta desviación típica. Utilizando la función LinRegTTest con estos datos, desplácese por las pantallas de salida hasta hallar s = 16,412.
Línea Y2 = -173,5 + 4,83x -2(16,4) y línea Y3 = -173,5 + 4,83x + 2(16,4)
donde ŷ = -173,5 + 4,83x es la línea de mejor ajuste. Y2 y Y3 tienen la misma pendiente que la línea de mejor ajuste.
Grafique el diagrama de dispersión con la línea de mejor ajuste en la ecuación Y1, luego introduzca las dos líneas adicionales como Y2 y Y3 en el editor de ecuaciones “Y=” y pulse ZOOM 9. Encontrará que el único punto de datos que no está entre las líneas Y2 y Y3 es el punto x = 65, y = 175. En la pantalla de la calculadora está apenas fuera de estas líneas. El valor atípico es el estudiante que obtuvo una calificación de 65 en el tercer examen y 175 en el examen final; este punto está a más de dos desviaciones típicas lejos de la línea de mejor ajuste.
A veces, un punto está tan cerca de las líneas utilizadas para marcar los valores atípicos en el gráfico que es difícil saber si el punto está entre las líneas o fuera de ellas. En una computadora, ampliar el gráfico puede ayudar; en la pantalla de una calculadora pequeña, el zoom puede hacer que el gráfico sea más claro. Tenga en cuenta que, cuando el gráfico no ofrece una imagen suficientemente clara, puede utilizar las comparaciones numéricas para identificar los valores atípicos.
Identificación numérica de los valores atípicos
En la siguiente tabla, las dos primeras columnas son los datos del tercer examen y del examen final. La tercera columna muestra los valores ŷ predichos, calculados a partir de la línea de mejor ajuste: ŷ = -173,5 + 4,83x. Los residuales, o errores, se han calculado en la cuarta columna de la tabla: valor y observado – valor y predicho = y – ŷ.
s es la desviación típica de todos los valores y – ŷ = ε donde n = el número total de puntos de datos. Si se calcula cada residual, se eleva al cuadrado y se suman los resultados, se obtiene la suma de errores al cuadrado (Sum of Squared Errors, SSE). La desviación típica de los residuales se calcula a partir de la SSE como:
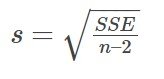
En vez de calcular el valor de s nosotros mismos, podemos calcular s con la computadora o la calculadora. Para este ejemplo, la función de la calculadora LinRegTTest calculó s = 16,4 como la desviación típica de los residuales 35; -17; 16; -6; -19; 9; 3; -1; -10; -9; -1.
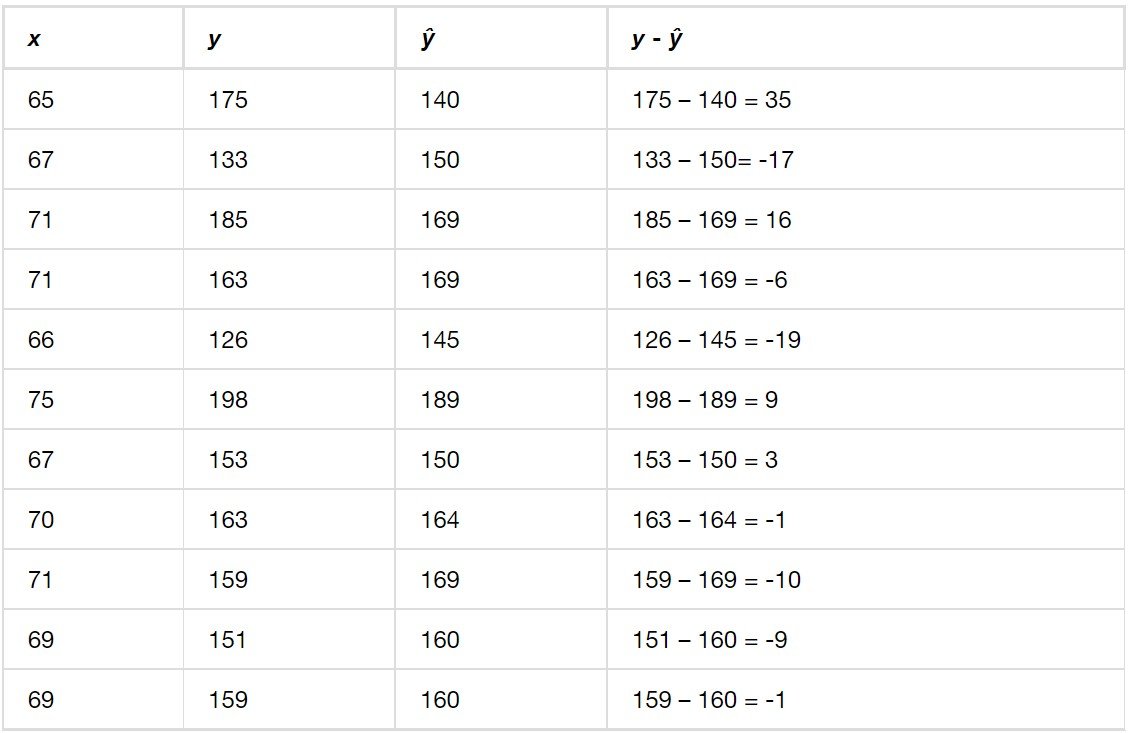
Buscamos todos los puntos de datos cuyo residual sea mayor que 2s = 2(16,4) = 32,8 o menor que –32.8. Compare estos valores con los residuales de la cuarta columna de la tabla. El único dato de este tipo es el del estudiante que tuvo una nota de 65 en el tercer examen y 175 en el examen final; el residual de este estudiante es 35.
¿Cómo afecta el valor atípico la línea de mejor ajuste?
Numérica y gráficamente, hemos identificado el punto (65, 175) como un valor atípico. Deberíamos repasar los datos de este punto para ver si hay algún problema con estos. Si hay un error, debemos corregirlo si es posible o eliminar los datos. Si son correctos, los dejaríamos en el conjunto de datos. Para este problema, supondremos que examinamos y descubrimos que estos datos atípicos son un error. Por lo tanto, seguiremos adelante y eliminaremos el valor atípico, para poder explorar cómo afecta los resultados, como experiencia de aprendizaje.
Calcule una nueva línea de mejor ajuste y el coeficiente de correlación con los diez puntos restantes:
En las calculadoras TI-83, TI-83+ y TI-84+, elimine el valor atípico de L1 y L2. Con la función LinRegTTest, la nueva línea de mejor ajuste y el coeficiente de correlación son:
ŷ = – 355,19 + 7,39x y r = 0,9121
La nueva línea con r = 0,9121 es una correlación más fuerte que la original (r = 0,6631) porque r = 0,9121 está más cerca de uno. Esto significa que la nueva línea se ajusta mejor a los diez valores de datos restantes. La línea puede predecir mejor la puntuación del examen final, dada la puntuación del tercer examen.
Identificación numérica de valores atípicos: Calcular s y buscar valores atípicos manualmente
Si no tiene la función LinRegTTest, puede calcular el valor atípico del primer ejemplo; haga lo siguiente.
Primero, eleve al cuadrado cada |y – ŷ|
Las potencias al cuadrado son: 352; 172; 162; 62; 192; 92; 32; 12; 102; 92; 12
A continuación, añada (sume) todos los términos |y – ŷ| al cuadrado mediante la fórmula:

A continuación, calcule s, la desviación típica de todos los valores y – ŷ = ε, donde n = el número total de puntos de datos.

A continuación, multiplique s por 2: (2)(16,47) = 32,94
32,94 está 2 desviaciones típicas lejos de la media de los valores y – ŷ.
Si midiéramos la distancia vertical desde cualquier punto de datos hasta el punto correspondiente de la línea de mejor ajuste y esa distancia fuera de al menos 2s, entonces consideraríamos que el punto de datos está “demasiado lejos” de la línea de mejor ajuste. A ese punto lo llamamos un potencial valor atípico.
Para el ejemplo, si alguno de los valores de y – ŷ| es al menos 32,94, el punto de datos correspondiente (x, y) es un posible valor atípico.
Para el problema del tercer examen o examen final, todos los |y – ŷ| son menores que 31,29, excepto el primero que es 35.
35 > 31,29 Es decir, |y – ŷ| ≥ (2)(s)
El punto que corresponde a |y – ŷ| = 35 es (65, 175). Por lo tanto, el punto de datos (65, 175) es un potencial valor atípico. Para este ejemplo, lo borraremos. (Recuerde que no siempre eliminamos un valor atípico).
El siguiente paso es calcular una nueva línea de mejor ajuste con los diez puntos restantes. La nueva línea de mejor ajuste y el coeficiente de correlación son:
ŷ = –355,19 + 7,39x y r = 0,9121
Fuente y licenciamiento
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0