Introducción
Muchas aplicaciones estadísticas en Psicología, Ciencias Sociales, Administración y Negocios y Ciencias Naturales involucran varios grupos. Por ejemplo, un ecologista está interesado en saber si la cantidad promedio de contaminación varía en varias masas de agua. A un sociólogo le interesa saber si la cantidad de ingresos que obtiene una persona varía según su educación. Un consumidor que busca un automóvil nuevo puede comparar el rendimiento por milla promedio de gasolina de varios modelos.
Para las pruebas de hipótesis que comparan promedios entre más de dos grupos, los estadísticos han desarrollado un método denominado “análisis de la varianza” (Analysis of Variance, ANOVA). En este capítulo estudiará la forma más simple de ANOVA llamada ANOVA de un factor o de una vía. También estudiará la distribución F, utilizada para el ANOVA de una vía, y la prueba de dos varianzas. Esto es solo un breve resumen del ANOVA de una vía. Estudiará este tema con mucho más detalle en futuros cursos de Estadística. El ANOVA de una vía, tal y como se presenta aquí, depende en gran medida de una calculadora o una computadora.

Contenidos temáticos
- ANOVA de una vía
- La distribución F y el cociente F
- Datos sobre la distribución F
- Prueba de dos varianzas
Desarrollo del tema
ANOVA de una vía
El propósito de una prueba de ANOVA de una vía es determinar la existencia de una diferencia estadísticamente significativa entre las medias de varios grupos. De hecho, la prueba usa varianzas para ayudar a determinar si las medias son iguales o no. Para realizar una prueba de ANOVA de una vía hay que cumplir cinco supuestos básicos:
- Se supone que cada población de la que se toma una muestra es normal.
- Todas las muestras se seleccionan al azar y son independientes.
- Se supone que las poblaciones tienen desviaciones típicas iguales (o varianzas).
- El factor es una variable categórica.
- La respuesta es una variable numérica.
Hipótesis nula y alternativa
La hipótesis nula es simplemente que todas las medias poblacionales del grupo son iguales. La hipótesis alternativa es que, al menos, un par de medias es diferente. Por ejemplo, si hay grupos k:
H0: μ1 = μ2 = μ3 = … = μk
Ha: Al menos dos de las medias del grupo μ1, μ2, μ3, …, μk no son iguales. Es decir, μi ≠ μj para algún i ≠ j.
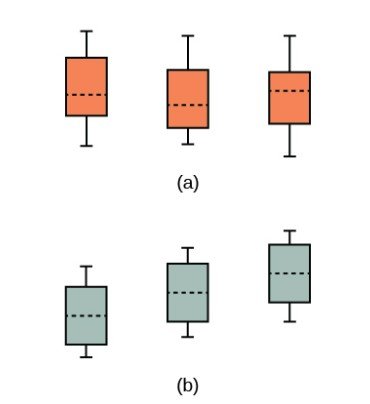
Los gráficos, un conjunto de diagramas de caja y bigotes que representan la distribución de los valores con las medias de los grupos indicadas por una línea horizontal que atraviesa la caja, ayudan a comprender la prueba de hipótesis. En el primer gráfico (diagrama de caja y bigotes rojo), H0: μ1 = μ2 = μ3 y las tres poblaciones tienen la misma distribución si la hipótesis nula es verdadera. La varianza de los datos combinados es, aproximadamente, igual a la varianza de cada una de las poblaciones.
Si la hipótesis nula es falsa, la varianza de los datos combinados es mayor, lo que se debe a las diferentes medias, como se muestra en el segundo gráfico (diagrama de caja verde).
La distribución F y el cociente F
La distribución utilizada para la prueba de hipótesis es nueva. Se llama distribuciónF, en honor al estadístico inglés Sir Ronald Fisher. El estadístico F es un cociente (una fracción). Hay dos conjuntos de grados de libertad; uno para el numerador y otro para el denominador.
Por ejemplo, si F sigue una distribución F y el número de grados de libertad para el numerador es cuatro y el número de grados de libertad para el denominador es diez, entonces F ~ F4, 10.
| Nota. La distribución F se deriva de la distribución t de Estudiante. Los valores de la distribución F son los cuadrados de los valores correspondientes de la distribución t. El ANOVA de una vía amplía la prueba t para comparar más de dos grupos. El alcance de esa derivación está más allá del nivel de este curso. Es preferible utilizar el ANOVA cuando hay más de dos grupos en lugar de realizar pruebas t por pares porque la realización de pruebas múltiples introduce la probabilidad de cometer un error de tipo 1. |
Para calcular el cociente F se hacen dos estimaciones de la varianza.
- Varianza entre muestras: Una estimación de σ2 que es la varianza de las medias muestrales multiplicada por n (cuando los tamaños de las muestras son iguales). Si las muestras son de diferentes tamaños, la varianza entre las muestras se pondera para tener en cuenta los diferentes tamaños de las muestras. La varianza también se denomina variación debido al tratamiento o variación explicada.
- Varianza dentro de las muestras: Una estimación de σ2 que es el promedio de las varianzas de la muestra (también conocida como varianza combinada). Cuando los tamaños de las muestras son diferentes, se pondera la varianza dentro de las muestras. La varianza también se denomina variación debido al error o variación no explicada.
- SSentre = la suma de los cuadrados que representa la variación entre las diferentes muestras
- SSdentro = la suma de los cuadrados que representa la variación dentro de las muestras debido al azar.
Hallar una “suma de cuadrados” significa sumar cantidades al cuadrado que, en algunos casos, pueden estar ponderadas. Utilizamos la suma de cuadrados para calcular la varianza de la muestra y la desviación típica de la muestra en Estadística Descriptiva.
MS significa “media cuadrática“ (mean square, MS). MSentre es la varianza entre grupos y MSdentro es la varianza dentro de los grupos.
Cálculo de la suma de cuadrados y de la media cuadrática

La prueba de ANOVA de una vía depende del hecho de que el MSentre puede estar influenciado por las diferencias poblacionales entre las medias de los distintos grupos. Dado que el MSdentro compara los valores de cada grupo con su propia media de grupo, el hecho de que las medias de los grupos puedan ser diferentes no afecta al MSdentro.
La hipótesis nula dice que todos los grupos son muestras de poblaciones que tienen la misma distribución normal. La hipótesis alternativa dice que, al menos, dos de los grupos de la muestra proceden de poblaciones con distribuciones normales diferentes. Si la hipótesis nula es verdadera, tanto MSentre como MSdentro deberían estimar el mismo valor.
| Nota. La hipótesis nula dice que todas las medias poblacionales del grupo son iguales. La hipótesis de igualdad de medias implica que las poblaciones tienen la misma distribución normal, ya que se supone que las poblaciones son normales y que tienen varianzas iguales. |
El cociente F o estadístico F
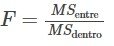
Si MSentre y MSdentro estiman el mismo valor (siguiendo la creencia de que H0 es verdadera), entonces el cociente F debería ser aproximadamente igual a uno. En su mayoría, solo los errores de muestreo contribuirían a variaciones alejadas de uno. Resulta que MSentre consiste en la varianza de la población más una varianza producida por las diferencias entre las muestras. MSdentro es una estimación de la varianza de la población. Dado que las varianzas son siempre positivas, si la hipótesis nula es falsa, MSentre será generalmente mayor que MSdentro. Entonces el cociente F será mayor que uno. Sin embargo, si el efecto de la población es pequeño, no es improbable que MSdentro sea mayor en una muestra determinada.
Los cálculos anteriores se hicieron con grupos de diferentes tamaños. Si los grupos son del mismo tamaño, los cálculos se simplifican un poco y el cociente F se puede escribir como:
Fórmula del cociente F cuando los grupos son del mismo tamaño

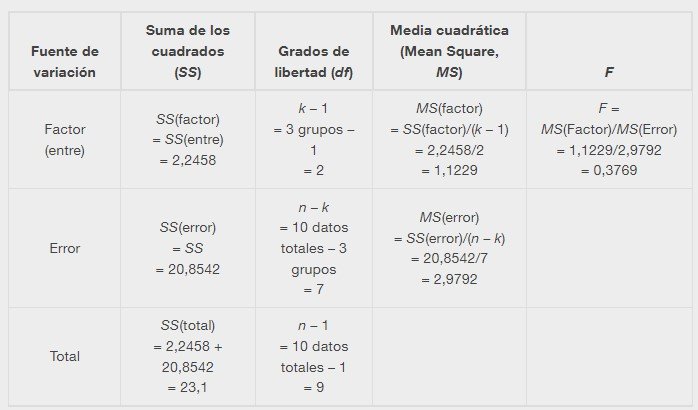
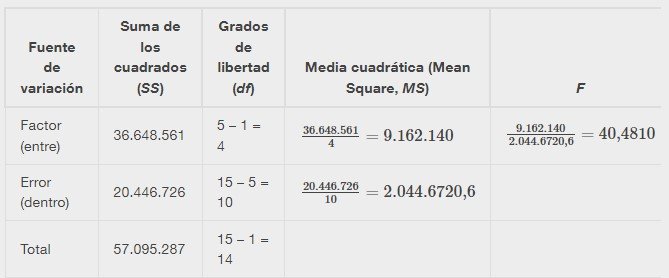
Los datos se suelen poner en una tabla para facilitar su visualización. Los resultados del ANOVA de una vía suelen mostrarse de esta manera en softwares.
| Fuente de variación | Suma de los cuadrados (SS) | Grados de libertad (df) | Media cuadrática (Mean Square, MS) | F |
|---|---|---|---|---|
| Factor (entre) | SS(factor) | k – 1 | MS(factor) = SS(factor)/(k – 1) | F = MS(Factor)/MS(Error) |
| Error | SS(error) | n – k | MS(error) = SS(error)/(n – k) | |
| Total | SS(total) | n – 1 |
Ejemplo:
Se van a probar tres planes de dieta diferentes para la pérdida media de peso. Las entradas de la tabla son las pérdidas de peso de los diferentes planes. Los resultados del ANOVA de una vía se muestran en la Tabla.
| Plan 1: n1 = 4 | Plan 2: n2 = 3 | Plan 3: n3 = 3 |
|---|---|---|
| 5 | 3,5 | 8 |
| 4,5 | 7 | 4 |
| 4 | 3,5 | |
| 3 | 4,5 |
s1 = 16,5, s2 =15, s3 = 15,5
A continuación se presentan los cálculos necesarios para completar la tabla de ANOVA de una vía. La tabla se utiliza para realizar una prueba de hipótesis.

| USO DE LAS CALCULADORAS TI-83, 83+, 84, 84+ Tabla de ANOVA de una vía: Las fórmulas para SS(total), SS(factor) = SS(entre) y SS(error) = SS(dentro) como se ha mostrado anteriormente. La misma información es proporcionada por la función de prueba de hipótesis de la calculadora TI ANOVA en STAT TESTS (la sintaxis es ANOVA(L1, L2, L3) donde L1, L2, L3 tienen los datos del Plan 1, Plan 2, Plan 3 respectivamente). |
La prueba de hipótesis del ANOVA de una vía es siempre de cola derecha porque los valores F más grandes están en la cola derecha de la curva de distribución F y tienden a hacernos rechazar H0.
Notación
La notación para la distribución F es F ~ Fdf(num),df(denom)
donde df(num) = dfentre y df(denom) = dfdentro
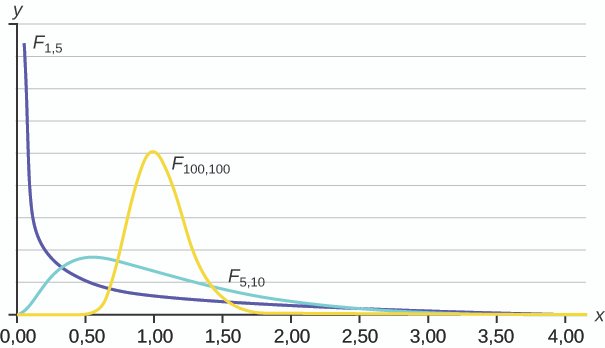
Datos sobre la distribución F
Estos son algunos datos sobre la distribución F.
- La curva no es simétrica, sino que está distorsionada hacia la derecha.
- Hay una curva diferente para cada conjunto de df.
- El estadístico F es mayor o igual a cero.
- A medida que aumentan los grados de libertad del numerador y del denominador, la curva se normaliza.
- Otros usos de la distribución F incluyen la comparación de dos varianzas y el análisis de varianza bidireccional. El análisis bidireccional queda fuera del alcance de este capítulo.
Ejemplo:
Volvamos al ejercicio de los tomates bola, las medias de los rendimientos de los tomates en las cinco condiciones de cubierta están representadas por μ1, μ2, μ3, μ4, μ5. Realizaremos una prueba de hipótesis para determinar si todas las medias son iguales o al menos una es diferente. Use un nivel de significación del 5 % y pruebe la hipótesis nula de que no hay diferencia en los rendimientos medios entre los cinco grupos contra la hipótesis alternativa de que, al menos, una media es diferente del resto.
Solución:
Las hipótesis nula y alternativa son:
H0: μ1 = μ2 = μ3 = μ4 = μ5
Ha: μi ≠ μj alguna i ≠ j
Los resultados del ANOVA de una vía se muestran en la Figura 13.5
Distribución para la prueba: F4, 10
df(num) = 5 – 1 = 4
df(denom) = 15 – 5 = 10
Estadístico de prueba: F = 4,4810
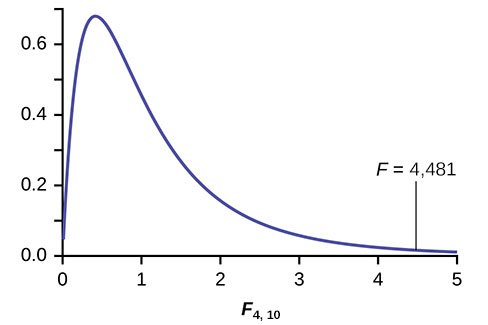
Declaración de probabilidad: valor p = P(F > 4,481) = 0,0248.
Compare α y el valor p: α = 0,05, valor p = 0,0248
Tome una decisión: Dado que α > valor p, rechazamos H0.
Conclusión: Al nivel de significación del 5 % tenemos pruebas razonablemente sólidas de que las diferencias en los rendimientos medios de las plantas de tomate de corte cultivadas en diferentes condiciones de cubierta de suelo es poco probable que se deban únicamente al azar. Podemos concluir que, al menos, algunas de las cubiertas produjeron diferentes rendimientos medios.
Pruebas de varianza
Otro uso de la distribución F es la prueba de dos varianzas. A menudo es conveniente comparar dos varianzas en vez de dos promedios. Por ejemplo, a los administradores del instituto universitario les gustaría que dos profesores que califiquen exámenes tengan la misma variación en su calificación. Para que una tapa se adapte a un recipiente, la variación de la tapa y del recipiente debe ser la misma. Un supermercado podría estar interesado en la variabilidad de los tiempos para procesar una compra en dos de sus cajas.
Para realizar una prueba F de dos varianzas, es importante que se cumplan estas condiciones:
- Las poblaciones de las que se extraen las dos muestras se distribuyen normalmente.
- Las dos poblaciones son independientes entre sí.
A diferencia de la mayoría de otras pruebas de este libro, la prueba F para la igualdad de dos varianzas es muy sensible a las desviaciones de la normalidad. Si las dos distribuciones no son normales, la prueba puede dar valores p más altos o más bajos de lo debido de forma imprevisible. Muchos textos sugieren a los estudiantes que no utilicen esta prueba en absoluto, pero en aras de la exhaustividad la incluimos aquí.


Fuentes de información
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0