Objetivos didácticos
- Representar los datos gráficamente e interpretar los gráficos: gráficos de tallo, histogramas y diagramas de caja.
- Reconocer, describir y calcular las medidas de localización de datos: cuartiles y percentiles.
- Reconocer, describir y calcular las medidas del centro de los datos: media, mediana y moda.
- Reconocer, describir y calcular las medidas de dispersión de los datos: varianza, desviación típica y rango.
Introducción
Una vez que haya recopilado los datos, ¿qué hará con ellos? Los datos se pueden describir y presentar en muchos formatos diferentes. Por ejemplo, supongamos que está interesado en comprar una casa en una zona determinada. Es posible que no tenga ni idea de los precios de las viviendas, por lo que puede pedirle a su agente inmobiliario que le dé un conjunto de datos de muestra de los precios. Mirar todos los precios de la muestra suele ser abrumador. Una mejor forma sería observar la mediana del precio y la variación de los precios. La mediana y la variación son solo dos formas que aprenderá para describir los datos. Su agente también puede proporcionarle un gráfico de los datos.
En esta lección estudiará las formas numéricas y gráficas de describir y mostrar sus datos. Esta área de la estadística se llama “Estadística Descriptiva”. Aprenderá a calcular y, lo que es más importante, a interpretar estas medidas y gráficos.
Un gráfico estadístico es una herramienta que ayuda a conocer la forma o la distribución de una muestra o de una población. Un gráfico puede ser una forma más eficaz de presentar los datos que una masa de números porque podemos ver dónde se agrupan los datos y dónde hay solo unos pocos valores de datos. Los periódicos e internet utilizan gráficos para mostrar tendencias y permitir a los lectores comparar rápidamente datos y cifras. Los estadísticos suelen hacer primero un gráfico de los datos para hacerse una idea de lo que arrojan. Luego, se pueden aplicar herramientas más formales.
Algunos de los tipos de gráficos que se utilizan para resumir y organizar los datos son el diagrama de puntos, el gráfico de barras, el histograma, el diagrama de tallo y hojas, el polígono de frecuencias (un tipo de gráfico de líneas discontinuas), el gráfico circular y el diagrama de caja. En este capítulo veremos brevemente gráficos de tallo y hoja, gráficos de líneas y gráficos de barras, así como polígonos de frecuencia y gráficos de series temporales. Haremos hincapié en los histogramas y los diagramas de caja.
Contenidos temáticos
- Gráficos de tallo y hoja (gráfico de tallo), gráficos de líneas y gráficos de barras
- Histogramas, polígonos de frecuencia y gráficos de series temporales
- Medidas de la ubicación de los datos
- Diagramas de caja
- Medidas del centro de los datos
- Distorsión y media, mediana y moda
Desarrollo del tema
1. Gráficos de tallo y hoja (gráfico de tallo), gráficos de líneas y gráficos de barras
Gráfico de tallo y hoja
Un gráfico sencillo, el gráfico de tallo y hoja o gráfico de tallo, procede del campo del análisis exploratorio de datos. Es una buena opción cuando los conjuntos de datos son pequeños. Para crear el gráfico, divida cada observación de datos en un tallo y una hoja. La hoja consta de un último dígito significativo. Por ejemplo, 23 tiene el tallo dos y la hoja tres. El número 432 tiene el tallo 43 y la hoja dos. Asimismo, el número 5.432 tiene el tallo 543 y la hoja dos. El decimal 9,3 tiene el tallo nueve y la hoja tres. Escriba los tallos en una línea vertical de menor a mayor. Dibuje una línea vertical a la derecha de los tallos. Luego, escriba las hojas en orden creciente junto a su correspondiente tallo.
El diagrama de tallo es una forma rápida de representar datos gráficamente y ofrece una imagen exacta de la información. Hay que buscar un patrón general y los valores atípicos. Un valor atípico es una observación de datos que no se ajusta al resto de los datos. A veces se le llama valor extremo. Cuando grafique un valor atípico parecerá que no se ajusta al patrón del gráfico. Algunos valores atípicos se deben a errores (por ejemplo, anotar 50 en vez de 500), mientras que otros pueden indicar que está ocurriendo algo inusual.
Ejemplo:
En la clase de Precálculo de primavera de Susan Dean las calificaciones del primer examen fueron las siguientes (de menor a mayor): 33; 42; 49; 49; 53; 55; 55; 61; 63; 67; 68; 68; 69; 69; 72; 73; 74; 78; 80; 83; 88; 88; 88; 90; 92; 94; 94; 94; 94; 96; 100
| Tallo | Hoja |
|---|---|
| 3 | 3 |
| 4 | 2 9 9 |
| 5 | 3 5 5 |
| 6 | 1 3 7 8 8 9 9 |
| 7 | 2 3 4 8 |
| 8 | 0 3 8 8 8 |
| 9 | 0 2 4 4 4 4 6 |
| 10 | 0 |
Gráfico de líneas
Otro tipo de gráfico que resulta útil para valores de datos específicos es el gráfico de líneas. En el gráfico de líneas en particular que se muestra en el siguiente ejemplo, el eje x (eje horizontal) está formado por los valores de los datos y el eje y (eje vertical) por puntos de frecuencia. Los puntos de frecuencia se conectan mediante segmentos de la línea.
Ejemplo:
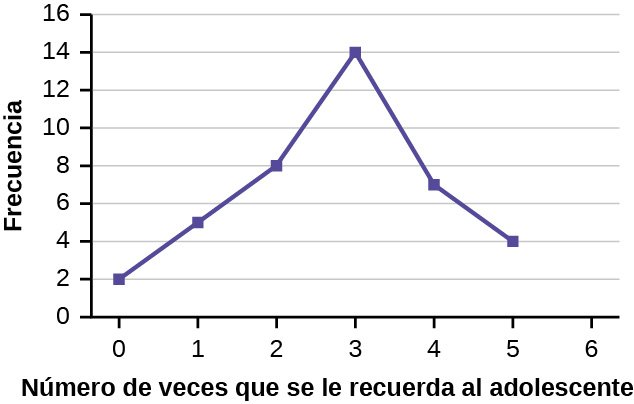
En una encuesta, se preguntó a 40 madres cuántas veces a la semana hay que recordarle a un adolescente que haga sus tareas. Los resultados son los siguientes:
| Número de veces que se le recuerda al adolescente | Frecuencia |
|---|---|
| 0 | 2 |
| 1 | 5 |
| 2 | 8 |
| 3 | 14 |
| 4 | 7 |
| 5 | 4 |
Gráficos de barras
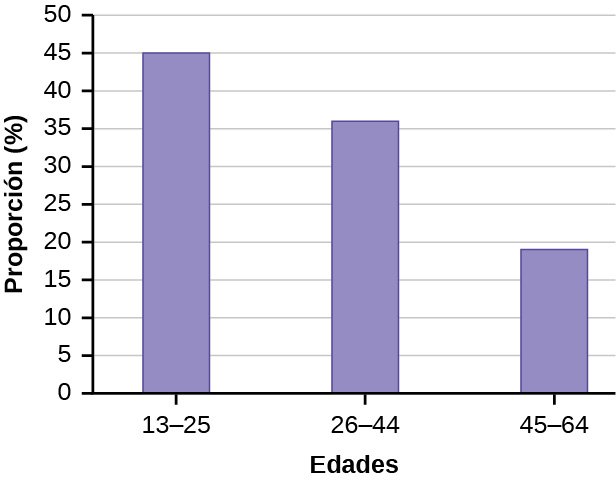
Los gráficos de barras están formados por barras separadas entre sí. Las barras pueden ser rectángulos o recuadros rectangulares (usados en representaciones tridimensionales), y pueden ser verticales u horizontales. El gráfico de barras que se muestra en el siguiente ejemplo tiene los grupos de edad representados en el eje x y las proporciones en el eje y.
Ejemplo
A finales de 2011, Facebook tenía más de 146 millones de usuarios en Estados Unidos. La siguiente tabla muestra tres grupos de edad, el número de usuarios en cada grupo de edad y la proporción (%) de usuarios en cada grupo de edad. Construya un gráfico de barras con estos datos.
| Grupos de edad | Número de usuarios de Facebook | Proporción (%) de usuarios de Facebook |
|---|---|---|
| 13-25 | 65.082.280 | 45 % |
| 26-44 | 53.300.200 | 36 % |
| 45-64 | 27.885.100 | 19 % |
2. Histogramas, polígonos de frecuencia y gráficos de series temporales
Histograma
Una de las ventajas de un histograma es que puede mostrar fácilmente grandes conjuntos de datos. Una regla general es utilizar un histograma cuando el conjunto de datos consta de 100 valores o más.
Un histograma está formado por recuadros contiguos (adyacentes). Tiene un eje horizontal y otro vertical. El eje horizontal está identificado con lo que representan los datos (por ejemplo, la distancia de su casa a la escuela). El eje vertical está identificado como frecuencia o frecuencia relativa (o porcentaje de frecuencia o probabilidad). El gráfico tendrá la misma forma con cualquiera de las dos etiquetas. El histograma (al igual que el diagrama de tallo) puede darle la forma de los datos, el centro y la dispersión de los datos.
La frecuencia relativa es igual a la frecuencia de un valor observado de los datos dividida por el número total de valores de datos de la muestra. (Recuerde que la frecuencia se define como el número de veces que se produce una respuesta). Si:
- f = frecuencia
- n = número total de valores de datos (o la suma de las frecuencias individuales) y
- RF = frecuencia relativa,
entonces:
RF=e/n
Por ejemplo, si tres estudiantes de la clase de Inglés del Sr. Ahab compuesta por 40 estudiantes obtuvieron del 90 % al 100 %, entonces, f = 3, n = 40 y RF = e/n = 3/40 = 0,075. El 7,5 % de los estudiantes obtuvieron del 90 % al 100 %. Del 90 % al 100 % son medidas cuantitativas.
Para construir un histograma, primero hay que decidir cuántas barras o intervalos (también llamados clases) representan los datos. Muchos histogramas constan de cinco a 15 barras o clases para mayor claridad. Hay que elegir el número de barras. Elija un punto de partida para que el primer intervalo sea menor que el valor más pequeño de los datos. Un punto de partida conveniente es un valor inferior llevado a un decimal más que el valor con más decimales. Por ejemplo, si el valor con más decimales es 6,1 y este es el valor más pequeño, un punto de partida conveniente es 6,05 (6,1 – 0,05 = 6,05). Decimos que 6,05 tiene más precisión. Si el valor con más decimales es 2,23 y el valor más bajo es 1,5, un punto de partida conveniente es 1,495 (1,5 – 0,005 = 1,495). Si el valor con más decimales es 3,234 y el valor más bajo es 1,0, un punto de partida conveniente es 0,9995 (1,0 – 0,0005 = 0,9995). Si todos los datos son enteros y el valor más pequeño es dos, un punto de partida conveniente es 1,5 (2 – 0,5 = 1,5). Además, cuando el punto de partida y otros límites se llevan a un decimal adicional, ningún valor de los datos caerá en un límite. Los dos siguientes ejemplos detallan cómo construir un histograma utilizando datos continuos y cómo crear un histograma utilizando datos discretos.
Ejemplo
Los siguientes datos son las estaturas (en pulgadas con una aproximación de media pulgada) de 100 jugadores hombres de fútbol semiprofesional. Las alturas son datos continuos, ya que la altura se mide.
60; 60,5; 61; 61; 61,5
63,5; 63,5; 63,5
64; 64; 64; 64; 64; 64; 64; 64,5; 64,5; 64,5; 64,5; 64,5; 64,5; 64,5; 64,5
66; 66; 66; 66; 66; 66; 66; 66; 66; 66; 66,5; 66,5; 66,5; 66,5; 66,5; 66,5; 66,5; 66,5; 66,5; 66,5; 66,5; 67; 67; 67; 67; 67; 67; 67; 67; 67; 67; 67; 67; 67,5; 67,5; 67,5; 67,5; 67,5; 67,5; 67,5
68; 68; 69; 69; 69; 69; 69; 69; 69; 69; 69; 69; 69,5; 69,5; 69,5; 69,5; 69,5
70; 70; 70; 70; 70; 70; 70,5; 70,5; 70,5; 71; 71; 71
72; 72; 72; 72,5; 72,5; 73; 73,5
74
El valor de datos más pequeño es 60. Como los datos con más decimales tienen un decimal (por ejemplo, 61,5), queremos que nuestro punto de partida tenga dos decimales. Dado que los números 0,5, 0,05, 0,005, etc. son números convenientes, utilice 0,05 y réstelo a 60, el valor más pequeño, para el punto de partida conveniente.
60 – 0,05 = 59,95 que es más preciso que, por ejemplo, 61,5 por un decimal. El punto de partida es, pues, 59,95.
El valor mayor es 74, por lo que 74 + 0,05 = 74,05 es el valor final.
Luego, calcule el ancho de cada barra o intervalo de clase. Para calcular este ancho, reste el punto inicial del valor final y divídalo entre el número de barras (debe elegir el número de barras que desee). Suponga que elige ocho barras.
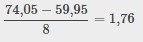
| NOTA Redondearemos a dos y haremos que cada barra o intervalo de clase tenga dos unidades de ancho. Redondear a dos es una forma de evitar que un valor caiga en un límite. El redondeo al número siguiente es a menudo necesario, incluso si va en contra de las reglas estándar de redondeo. Para este ejemplo, utilizar 1,76 como ancho también funcionaría. Una pauta que siguen algunos para el número de barras o intervalos de clase es tomar la raíz cuadrada del número de valores de datos y luego redondear al número entero más cercano, si es necesario. Por ejemplo, si hay 150 valores de datos, tome la raíz cuadrada de 150 y redondee a 12 barras o intervalos. |
Los límites son:
- 59,95
- 59,95 + 2 = 61,95
- 61,95 + 2 = 63,95
- 63,95 + 2 = 65,95
- 65,95 + 2 = 67,95
- 67,95 + 2 = 69,95
- 69,95 + 2 = 71,95
- 71,95 + 2 = 73,95
- 73,95 + 2 = 75,95
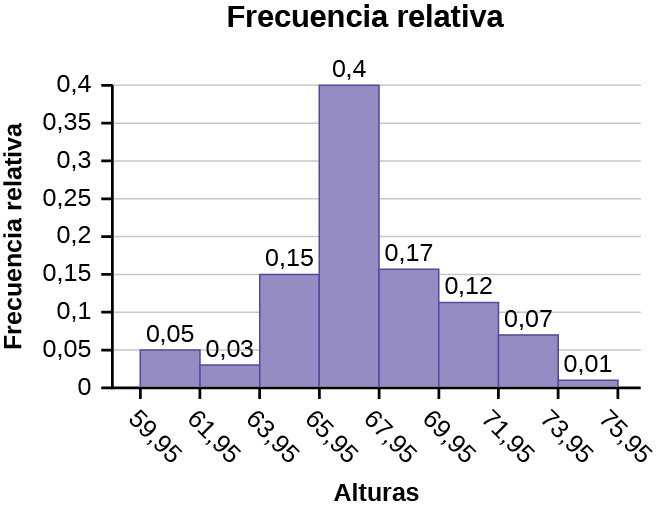
Las alturas de 60 a 61,5 pulgadas están en el intervalo de 59,95 a 61,95. Las alturas que son 63,5 están en el intervalo de 61,95 a 63,95. Las alturas que van de 64 a 64,5 están en el intervalo de 63,95 a 65,95. Las alturas de 66 a 67,5 están en el intervalo de 65,95 a 67,95. Las alturas de 68 a 69,5 están en el intervalo de 67,95 a 69,95. Las alturas de 70 a 71 están en el intervalo de 69,95 a 71,95. Las alturas de 72 a 73,5 están en el intervalo de 71,95 a 73,95. La altura 74 está en el intervalo de 73,95 a 75,95.
El siguiente histograma muestra las alturas en el eje x y la frecuencia relativa en el eje y.
Polígonos de frecuencia
Los polígonos de frecuencias son análogos a los gráficos de líneas y, al igual que los gráficos de líneas facilitan la interpretación visual de los datos continuos, también lo hacen los polígonos de frecuencias.
Para construir un polígono de frecuencias, primero hay que examinar los datos y decidir el número de intervalos, o intervalos de clase, que se van a utilizar en los ejes x y y. Después de elegir los rangos apropiados, comience a trazar los puntos de datos. Después de trazar todos los puntos, dibuje segmentos de línea para conectarlos.
Ejemplo
Se construyó un polígono de frecuencias a partir de la tabla de frecuencias que aparece a continuación.
Distribución de frecuencias de las calificaciones del examen final de Cálculo
| Límite inferior | Límite superior | Frecuencia | Frecuencia acumulada |
|---|---|---|---|
| 49,5 | 59,5 | 5 | 5 |
| 59,5 | 69,5 | 10 | 15 |
| 69,5 | 79,5 | 30 | 45 |
| 79,5 | 89,5 | 40 | 85 |
| 89,5 | 99,5 | 15 | 100 |
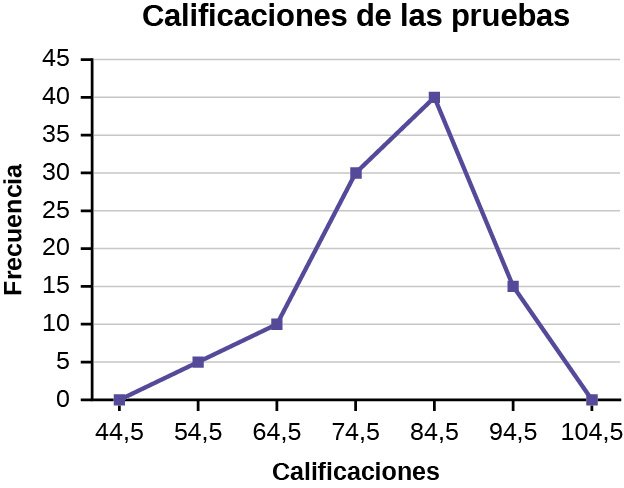
La primera etiqueta del eje x es 44,5. Esto representa un intervalo que va de 39,5 a 49,5. Dado que la calificación más baja de la prueba es 54,5, este intervalo se utiliza solo para permitir que el gráfico toque el eje x. El punto identificado como 54,5 representa el siguiente intervalo, o el primer intervalo “real” de la tabla, y contiene cinco calificaciones. Este razonamiento se sigue para cada uno de los intervalos restantes, con el punto 104,5 que representa el intervalo de 99,5 a 109,5. De nuevo, este intervalo no contiene datos y solo se utiliza para que el gráfico toque el eje x. Observando el gráfico, decimos que esta distribución está distorsionada porque un lado del gráfico no es un espejo del otro.
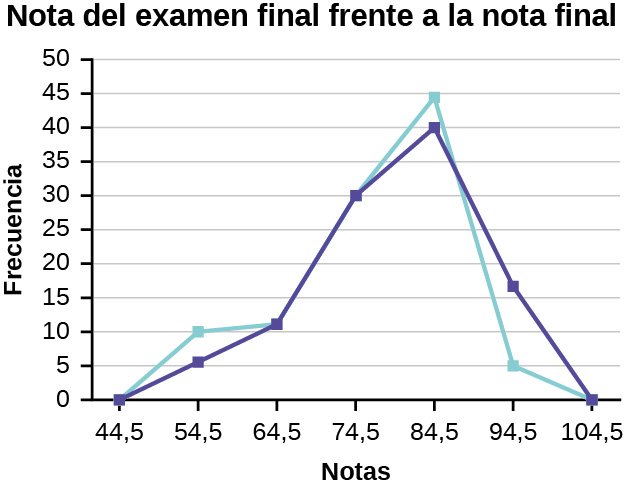
Los polígonos de frecuencia son útiles para comparar distribuciones. Esto se consigue superponiendo los polígonos de frecuencia dibujados para diferentes conjuntos de datos.
Ejemplo
Construiremos un polígono de frecuencias superpuestas comparando las puntuaciones de las calificaciones del examen final de Cálculo, con la nota numérica final de los estudiantes.
Distribución de frecuencias de las calificaciones del examen final de Cálculo
| Límite inferior | Límite superior | Frecuencia | Frecuencia acumulada |
|---|---|---|---|
| 49,5 | 59,5 | 5 | 5 |
| 59,5 | 69,5 | 10 | 15 |
| 69,5 | 79,5 | 30 | 45 |
| 79,5 | 89,5 | 40 | 85 |
| 89,5 | 99,5 | 15 | 100 |
Distribución de frecuencias de las notas finales de Cálculo
| Límite inferior | Límite superior | Frecuencia | Frecuencia acumulada |
|---|---|---|---|
| 49,5 | 59,5 | 10 | 10 |
| 59,5 | 69,5 | 10 | 20 |
| 69,5 | 79,5 | 30 | 50 |
| 79,5 | 89,5 | 45 | 95 |
| 89,5 | 99,5 | 5 | 100 |
Supongamos que queremos estudiar el rango de temperaturas de una región durante todo un mes. Todos los días a mediodía anotamos la temperatura y la anotamos en un registro. Con estos datos se podrían realizar diversos estudios estadísticos. Podemos hallar la media o la mediana de la temperatura del mes. Podemos construir un histograma que muestre el número de días en que las temperaturas alcanzan un determinado rango de valores. Sin embargo, todos estos métodos ignoran una parte de los datos que hemos recopilado.
Una característica de los datos que podemos considerar es la del tiempo. Dado que cada fecha se empareja con la lectura de la temperatura del día, no tenemos que pensar que los datos son aleatorios. En cambio, podemos utilizar los tiempos indicados para imponer un orden cronológico a los datos. Un gráfico que reconoce esta ordenación y muestra la evolución de la temperatura a medida que avanza el mes se denomina gráfico de series temporales.
Construcción de un gráfico de series temporales
Para construir un gráfico de series temporales debemos observar las dos partes de nuestro conjunto de datos emparejados. Comenzamos con un sistema de coordenadas cartesianas estándar. El eje horizontal se utiliza para trazar la fecha o los incrementos de tiempo, y el eje vertical se utiliza para trazar los valores de la variable que estamos midiendo. De este modo, hacemos que cada punto del gráfico corresponda a una fecha y a una cantidad medida. Los puntos del gráfico suelen estar conectados por líneas rectas en el orden en que se producen.
Ejemplo
Los siguientes datos muestran el Índice de Precios del Consumidor (IPC) Anual, cada mes, durante diez años. Construya un gráfico de series temporales solo para los datos del Índice de Precios del Consumidor Anual.
| Año | Ene | Feb | Mar | Abr | May | Jun | Jul |
|---|---|---|---|---|---|---|---|
| 2003 | 181,7 | 183,1 | 184,2 | 183,8 | 183,5 | 183,7 | 183,9 |
| 2004 | 185,2 | 186,2 | 187,4 | 188,0 | 189,1 | 189,7 | 189,4 |
| 2005 | 190,7 | 191,8 | 193,3 | 194,6 | 194,4 | 194,5 | 195,4 |
| 2006 | 198,3 | 198,7 | 199,8 | 201,5 | 202,5 | 202,9 | 203,5 |
| 2007 | 202,416 | 203,499 | 205,352 | 206,686 | 207,949 | 208,352 | 208,299 |
| 2008 | 211,080 | 211,693 | 213,528 | 214,823 | 216,632 | 218,815 | 219,964 |
| 2009 | 211,143 | 212,193 | 212,709 | 213,240 | 213,856 | 215,693 | 215,351 |
| 2010 | 216,687 | 216,741 | 217,631 | 218,009 | 218,178 | 217,965 | 218,011 |
| 2011 | 220,223 | 221,309 | 223,467 | 224,906 | 225,964 | 225,722 | 225,922 |
| 2012 | 226,665 | 227,663 | 229,392 | 230,085 | 229,815 | 229,478 | 229,104 |
| Año | Ago | Sep | Oct | Nov | Dic | Anual |
|---|---|---|---|---|---|---|
| 2003 | 184,6 | 185,2 | 185,0 | 184,5 | 184,3 | 184,0 |
| 2004 | 189,5 | 189,9 | 190,9 | 191,0 | 190,3 | 188,9 |
| 2005 | 196,4 | 198,8 | 199,2 | 197,6 | 196,8 | 195,3 |
| 2006 | 203,9 | 202,9 | 201,8 | 201,5 | 201,8 | 201,6 |
| 2007 | 207,917 | 208,490 | 208,936 | 210,177 | 210,036 | 207,342 |
| 2008 | 219,086 | 218,783 | 216,573 | 212,425 | 210,228 | 215,303 |
| 2009 | 215,834 | 215,969 | 216,177 | 216,330 | 215,949 | 214,537 |
| 2010 | 218,312 | 218,439 | 218,711 | 218,803 | 219,179 | 218,056 |
| 2011 | 226,545 | 226,889 | 226,421 | 226,230 | 225,672 | 224,939 |
| 2012 | 230,379 | 231,407 | 231,317 | 230,221 | 229,601 | 229,594 |
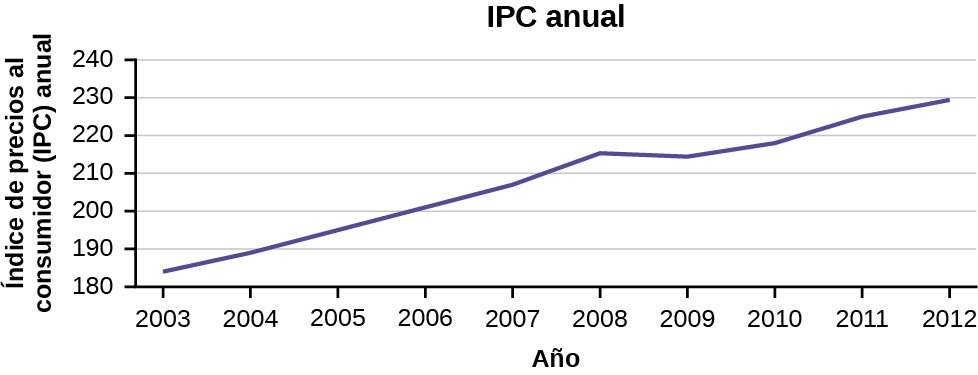
Usos de un gráfico de series temporales
Los gráficos de series temporales son herramientas importantes en diversas aplicaciones de la estadística. Cuando se registran los valores de una misma variable durante un largo periodo, a veces, es difícil discernir cualquier tendencia o patrón. Sin embargo, una vez que los mismos puntos de datos se muestran gráficamente, algunas características saltan a la vista. Los gráficos de series temporales facilitan la detección de tendencias.
3. Medidas de la ubicación de los datos
Las medidas habituales de localización son cuartiles y percentiles
Los cuartiles son percentiles especiales. El primer cuartil, Q1, es igual que el percentil 25, y el tercer cuartil, Q3, es igual que el percentil 75. La mediana, M, se denomina tanto el segundo cuartil como el percentil 50.
Para calcular cuartiles y percentiles, los datos se deben ordenar de menor a mayor. Los cuartiles dividen los datos ordenados en cuartos. Los percentiles dividen los datos ordenados en centésimas. Obtener una calificación en el percentil 90 de un examen no significa, necesariamente, que haya obtenido el 90 % en una prueba. Significa que el 90 % de las calificaciones de las pruebas son iguales o inferiores a su calificación y el 10 % de las calificaciones de las pruebas son iguales o superiores a su calificación.
Los percentiles son útiles para comparar valores. Por esta razón, universidades e institutos universitarios usan ampliamente los percentiles. Uno de los casos en los que institutos universitarios y universidades utilizan los percentiles es cuando los resultados del SAT se emplean para determinar una calificación mínima del examen que se utilizará como factor de aceptación. Por ejemplo, supongamos que Duke acepta calificaciones del SAT iguales o superiores al percentil 75. Eso se traduce en una calificación de, al menos, 1.220.
Los percentiles se utilizan sobre todo con poblaciones muy grandes. Por lo tanto, si se dijera que el 90 % de las calificaciones de las pruebas son menores (y no iguales o menores) que su calificación, sería aceptable porque eliminar un valor de datos particular no es significativo.
La mediana es un número que mide el “centro” de los datos. Se puede pensar en la mediana como el “valor medio”, pero no tiene por qué ser uno de los valores observados. Es un número que separa los datos ordenados en mitades. La mitad de los valores son iguales o menores que la mediana, y la mitad de los valores son iguales o mayores. Por ejemplo, considere los siguientes datos.
1; 11,5; 6; 7,2; 4; 8; 9; 10; 6,8; 8,3; 2; 2; 10; 1
Ordenado de menor a mayor:
1; 1; 2; 2; 4; 6; 6,8; 7,2; 8; 8,3; 9; 10; 10; 11,5
Como hay 14 observaciones, la mediana está entre el séptimo valor, 6,8, y el octavo, 7,2. Para hallar la mediana, sume los dos valores y divídalos entre dos.
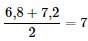
La mediana es siete. La mitad de los valores son menores que siete y la mitad de los valores son mayores que siete.
Los cuartiles son números que separan los datos en cuartos. Los cuartiles pueden o no formar parte de los datos. Para hallar los cuartiles, primero hay que hallar la mediana o el segundo cuartil. El primer cuartil, Q1, es el valor central de la mitad inferior de los datos, y el tercer cuartil, Q3, es el valor central, o la mediana, de la mitad superior de los datos. Para hacerse una idea, considere el mismo conjunto de datos:
1; 1; 2; 2; 4; 6; 6,8; 7,2; 8; 8,3; 9; 10; 10; 11,5
La mediana o segundo cuartil es siete. La mitad inferior de los datos son 1; 1; 2; 2; 4; 6; 6,8. El valor central de la mitad inferior es dos.
1; 1; 2; 2; 4; 6; 6,8
El número dos, que forma parte de los datos, es el primer cuartil. Una cuarta parte de los conjuntos de valores son iguales o inferiores a dos y tres cuartas partes de los valores son superiores a dos.
La mitad superior de los datos es 7,2; 8; 8,3; 9; 10; 10; 11,5. El valor central de la mitad superior es nueve.
El tercer cuartil, Q3, es nueve. Tres cuartas partes (75 %) del conjunto de datos ordenados son menores de nueve. Una cuarta parte (25 %) del conjunto de datos ordenados son mayores de nueve. El tercer cuartil forma parte del conjunto de datos de este ejemplo.
El rango intercuartil es un número que indica la dispersión de la mitad central o del 50 % central de los datos. Es la diferencia entre el tercer cuartil (Q3) y el primer cuartil (Q1).
IQR = Q3 – Q1
El IQR puede ayudar a determinar posibles valores atípicos. Se sospecha que un valor es un posible valor atípico si está menos de (1,5)(IQR) por debajo del primer cuartil o más de (1,5)(IQR) por encima del tercer cuartil. Los posibles valores atípicos siempre requieren una investigación más profunda.
Nota. Un valor atípico potencial es un punto de datos que es significativamente diferente de los otros puntos de datos. Estos puntos de datos especiales pueden ser errores o algún tipo de anormalidad o pueden ser una clave para entender los datos.
Ejemplo
Para los siguientes 13 precios de bienes raíces, calcule el IQR y determine si algún precio es un posible valor atípico. Los precios están en dólares.
389.950; 230.500; 158.000; 479.000; 639.000; 114.950; 5.500.000; 387.000; 659.000; 529.000; 575.000; 488.800; 1.095.000
Solución
Ordene los datos de menor a mayor.
114.950; 158.000; 230.500; 387.000; 389.950; 479.000; 488.800; 529.000; 575.000; 639.000; 659.000; 1.095.000; 5.500.000
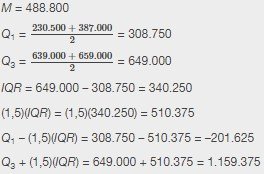
Ningún precio de la vivienda es inferior a –201.625. Sin embargo, 5.500.000 son más que 1.159.375. Por lo tanto, 5.500.000 es un posible valor atípico.
Una fórmula para hallar el percentil k
Si investiga un poco, hallará varias fórmulas para calcular el percentil k Aquí está una de ellas.
k = el percentil k. Puede o no formar parte de los datos.
i = el índice (clasificación o posición de un valor de datos)
n = el número total de datos
- Ordene los datos de menor a mayor.
- Calcule i=k/100(n+1)i=k/100(n+1)
- Si i es un número entero, el percentil k es el valor de los datos en la posición i en el conjunto ordenado de datos.
- Si i no es un entero, entonces redondee i hacia arriba o redondee i hacia abajo a los enteros más cercanos. Promedia los dos valores de los datos en estas dos posiciones en el conjunto de datos ordenados. Esto es más fácil de entender con un ejemplo.
Una fórmula para hallar el percentil de un valor en un conjunto de datos
- Ordene los datos de menor a mayor.
- x = el número de valores de datos contando desde la parte inferior de la lista de datos hasta, pero sin incluir, el valor de datos para el que se desea hallar el percentil.
- y = el número de valores de datos iguales al valor de los datos para los que se quiere hallar el percentil.
- n = el número total de datos.
- Calcule x+0,5y/n(100). Luego, redondee al número entero más cercano.
Interpretación de percentiles, cuartiles y mediana
Un percentil indica la posición relativa de un valor de datos cuando estos se ordenan numéricamente de menor a mayor. Los porcentajes de los valores de los datos son menores o iguales al percentil p. Por ejemplo, el 15 % de los valores de los datos son inferiores o iguales al percentil 15.
- Los percentiles bajos corresponden siempre a valores de datos más bajos.
- Los percentiles altos corresponden siempre a valores de datos más altos.
Un percentil puede corresponder o no a un juicio de valor sobre si es “bueno” o “deficiente”. La interpretación de si un determinado percentil es “bueno” o “deficiente” depende del contexto de la situación a la que se aplican los datos. En algunas situaciones, un percentil bajo se consideraría “bueno”; en otros contextos, un percentil alto podría considerarse “bueno”. En muchas situaciones no se aplica ningún juicio de valor.
Entender cómo interpretar correctamente los percentiles es importante no solo a la hora de describir los datos, sino también a la hora de calcular las probabilidades en capítulos posteriores de este texto.
Nota. Al escribir la interpretación de un percentil en el contexto de los datos dados, la oración debe contener la siguiente información.
- información sobre el contexto de la situación considerada.
- el valor del dato (valor de la variable) que representa el percentil.
- el porcentaje de personas o elementos con valores de datos por debajo del percentil.
- el porcentaje de personas o elementos con valores de datos por encima del percentil.
4. Diagramas de caja
Los diagramas de caja (también llamados diagramas de caja y bigotes o gráficos de caja y bigotes) ofrecen una buena imagen gráfica de la concentración de los datos. También muestran lo lejos que están los valores extremos de la mayoría de los datos. Un diagrama de caja se construye a partir de cinco valores: el valor mínimo, el primer cuartil, la mediana, el tercer cuartil y el valor máximo. Utilizamos estos valores para comparar la proximidad de otros valores de datos.
Para construir un diagrama de caja, utilice una línea numérica horizontal o vertical y una caja rectangular. Los valores de datos más pequeños y más grandes marcan los puntos finales del eje. El primer cuartil marca un extremo de la caja y el tercer cuartil marca el otro extremo de la caja. Aproximadamente el 50 % de los datos están dentro de la caja. Los “bigotes” se extienden desde los extremos de la caja hasta los valores de datos más pequeños y más grandes. La mediana o el segundo cuartil pueden estar entre el primer y el tercer cuartil, o puede ser uno, el otro, o ambos. El diagrama de caja ofrece una buena y rápida imagen de los datos.
Nota. Es posible que encuentre diagramas de caja y bigotes con puntos que marcan los valores atípicos. En esos casos, los bigotes no se extienden hasta los valores mínimos y máximos.
Consideremos, de nuevo, este conjunto de datos.
1; 1; 2; 2; 4; 6; 6,8; 7,2; 8; 8,3; 9; 10; 10; 11,5
El primer cuartil es dos, la mediana es siete y el tercer cuartil es nueve. El valor más pequeño es uno y el más grande es 11,5. La siguiente imagen muestra el diagrama de caja construido.

Los dos bigotes se extienden desde el primer cuartil hasta el valor más pequeño y desde el tercer cuartil hasta el valor más grande. La mediana se muestra con una línea discontinua.
Nota. Es importante comenzar un diagrama de caja con una línea numérica a escala. De lo contrario, el diagrama de caja puede no ser útil.
Ejemplo
Los siguientes datos son las estaturas de 40 estudiantes en una clase de Estadística.
59; 60; 61; 62; 62; 63; 63; 64; 64; 64; 65; 65; 65; 65; 65; 65; 65; 65; 65; 66; 66; 67; 67; 68; 68; 69; 70; 70; 70; 70; 70; 71; 71; 72; 72; 73; 74; 74; 75; 77
Construya un diagrama de caja con las siguientes propiedades; las instrucciones de la calculadora para los valores mínimo y máximo, así como los cuartiles, siguen el ejemplo.
- Valor mínimo = 59
- Valor máximo = 77
- Q1: Primer cuartil = 64,5
- Q2: Segundo cuartil o mediana= 66
- Q3: Tercer cuartil = 70

- Cada trimestre tiene aproximadamente el 25 % de los datos.
- Los diferenciales de los cuatro trimestres son 64,5 – 59 = 5,5 (primer trimestre), 66 – 64,5 = 1,5 (segundo trimestre), 70 – 66 = 4 (tercer trimestre) y 77 – 70 = 7 (cuarto trimestre). Así, el segundo trimestre tiene el menor diferencial y el cuarto el mayor.
- Rango = valor máximo – el valor mínimo = 77 – 59 = 18
- Rango intercuartil: IQR = Q3 – Q1 = 70 – 64,5 = 5,5.
- El intervalo 59-65 tiene más del 25 % de los datos, por lo que tiene más datos que el intervalo 66-70, que tiene el 25 % de los datos.
- El 50 % de los datos (la mitad) tiene un rango de 5,5 pulgadas.
En algunos conjuntos de datos, el valor más grande, el valor más pequeño, el primer cuartil, la mediana y el tercer cuartil pueden ser los mismos. Por ejemplo, puede tener un conjunto de datos en el que la mediana y el tercer cuartil son iguales. En este caso, el diagrama no tendría una línea de puntos dentro de la caja que muestra la mediana. El lado derecho del cuadro mostraría tanto el tercer cuartil como la mediana. Por ejemplo, si el valor más pequeño y el primer cuartil fuesen ambos uno, la mediana y el tercer cuartil fuesen ambos cinco, y el valor más grande fuese siete, el diagrama de caja tendría el siguiente aspecto:
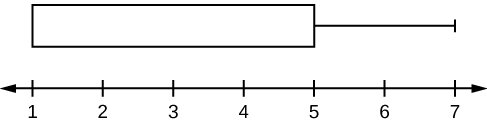
En este caso, al menos el 25 % de los valores son iguales a uno. El 25 % de los valores están entre uno y cinco, ambos inclusive. Al menos el 25 % de los valores son iguales a cinco. El 25 % de los valores más altos se sitúan entre el cinco y el siete, ambos inclusive.
5. Medidas del centro de los datos
El “centro” de un conjunto de datos también es una forma de describir la ubicación. Las dos medidas más utilizadas del “centro” de los datos son la media (promedio) y la mediana. Para calcular el peso medio de 50 personas, sume los 50 pesos y los divide entre 50. Para calcular la mediana del peso de las 50 personas, ordene los datos y halle el número que divide los datos en dos partes iguales. La mediana suele ser una mejor medida del centro cuando hay valores extremos o atípicos porque no se ve afectada por los valores numéricos precisos de los atípicos. La media es la medida más común del centro.
Nota. Las palabras “media” y “promedio” se suelen usar indistintamente. La sustitución de una palabra por otra es una práctica habitual. El término técnico es “media aritmética” y “promedio” es técnicamente un lugar central. Sin embargo, en la práctica, entre los no estadísticos, se suele aceptar “promedio” por “media aritmética”.
Cuando cada valor del conjunto de datos no es único, la media se puede calcular multiplicando cada valor distinto por su frecuencia y dividiendo después la suma por el número total de valores de los datos. La letra utilizada para representar la media muestral es una x con una barra encima (se pronuncia “barra de x”):
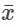
La letra griega μ (se pronuncia “mu”) representa la media de la población. Uno de los requisitos para que la media muestral sea una buena estimación de la media de la población es que la muestra tomada sea realmente aleatoria.
Para ver que ambas formas de calcular la media son iguales, considere la muestra:
1; 1; 1; 2; 2; 3; 4; 4; 4; 4; 4
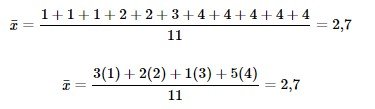
En el segundo cálculo, las frecuencias son 3, 2, 1 y 5.
Puede hallar rápidamente la ubicación de la mediana utilizando la expresión n+1/2.
La letra n es el número total de valores de datos en la muestra. Si n es un número impar, la mediana es el valor del centro de los datos ordenados (ordenados de menor a mayor). Si n es un número par, la mediana es igual a los dos valores del centro sumados y divididos entre dos después de ordenar los datos. Por ejemplo, si el número total de valores de datos es de 97, entonces n+1/2 = 97+1/2 = 49. La mediana es el 49.º valor de los datos ordenados. Si el número total de valores de datos es 100, entonces n+1/2 = 100+1/2 = 50,5. La mediana está a medio camino entre los valores 50.º y 51.º. La ubicación de la mediana y el valor de la mediana no son lo mismo. La letra M mayúscula se utiliza a menudo para representar la mediana. El siguiente ejemplo ilustra la ubicación de la mediana y su valor.
Ejemplo
Los datos sobre el sida que indican el número de meses que vive un paciente con sida después de tomar un nuevo medicamento con anticuerpos son los siguientes (de menor a mayor):
3; 4; 8; 8; 10; 11; 12; 13; 14; 15; 15; 16; 16; 17; 17; 18; 21; 22; 22; 24; 24; 25; 26; 26; 27; 27; 29; 29; 31; 32; 33; 33; 34; 34; 35; 37; 40; 44; 44; 47;
El cálculo de la media es:

Otra medida del centro es la moda. La moda es el valor más frecuente. Puede haber más de una moda en un conjunto de datos siempre que esos valores tengan la misma frecuencia y esta sea la más alta. Un conjunto de datos con dos modas se denomina bimodal.
Ejemplo
Las calificaciones de los exámenes de Estadística de 20 estudiantes son las siguientes:
50; 53; 59; 59; 63; 63; 72; 72; 72; 72; 72; 76; 78; 81; 83; 84; 84; 84; 90; 93
La calificación más frecuente es 72, que aparece cinco veces. Moda = 72.
La ley de los grandes números y la media
La ley de los grandes números dice que, si se toman muestras de tamaño cada vez mayor de cualquier población, entonces la media de la muestra es muy probable que se acerque cada vez más a µ. Esto se analiza con más detalle más adelante en el texto.
Distribuciones muestrales y estadística de una distribución muestral
Se puede pensar en una distribución de muestreo como una distribución de frecuencia relativa con un gran número de muestras (vea la sección Muestreo y datos para hacer un repaso de la frecuencia relativa). Supongamos que se pregunta a treinta estudiantes seleccionados al azar el número de películas que vieron la semana anterior. Los resultados se encuentran en la tabla de frecuencias relativas que se muestra a continuación.
| N.º de películas | Frecuencia relativa |
|---|---|
| 0 | 5/30 |
| 1 | 15/30 |
| 2 | 6/30 |
| 3 | 3/30 |
| 4 | 1/30 |
Si se deja que el número de muestras sea muy grande (por ejemplo, 300 millones o más), la tabla de frecuencias relativas se convierte en una distribución de frecuencias relativas.
Una estadística es un número calculado a partir de una muestra. Algunos ejemplos de estadísticas son la media, la mediana y la moda, entre otros. La media muestral es un ejemplo de estadística que estima la media poblacional μ.
Cálculo de la media de las tablas de frecuencias agrupadas
Cuando solo se dispone de datos agrupados no se conocen los valores individuales de los datos (solo conocemos los intervalos y las frecuencias de los intervalos); por lo tanto, no se puede calcular una media exacta para el conjunto de datos. Lo que debemos hacer es estimar la media real calculando la media de una tabla de frecuencias. Una tabla de frecuencias es una representación de datos en la que se muestran datos agrupados junto con las frecuencias correspondientes. Para calcular la media de una tabla de frecuencias agrupadas podemos aplicar la definición básica de media: media = suma de los datos/número de los valores de los datos. Simplemente tenemos que modificar la definición para que se ajuste a las restricciones de una tabla de frecuencias.
Como no conocemos los valores individuales de los datos podemos hallar el punto medio de cada intervalo. El punto medio es límite inferior + límite superior/2. Ahora podemos modificar la definición de la media para que sea Tabla de media de la frecuencia=∑em/∑e donde f = la frecuencia del intervalo y m = el punto medio del intervalo.
Ejemplo
Se presenta una tabla de frecuencias que muestra la prueba estadística anterior del profesor Blount. Calcule la mejor estimación de la media de la clase.
| Intervalo de grado | Número de estudiantes |
|---|---|
| 50–56,5 | 1 |
| 56,5–62,5 | 0 |
| 62,5–68,5 | 4 |
| 68,5–74,5 | 4 |
| 74,5–80,5 | 2 |
| 80,5–86,5 | 3 |
| 86,5–92,5 | 4 |
| 92,5–98,5 | 1 |
| Intervalo de grado | Punto medio |
|---|---|
| 50–56,5 | 53,25 |
| 56,5–62,5 | 59,5 |
| 62,5–68,5 | 65,5 |
| 68,5–74,5 | 71,5 |
| 74,5–80,5 | 77,5 |
| 80,5–86,5 | 83,5 |
| 86,5–92,5 | 89,5 |
| 92,5–98,5 | 95,5 |
- Calcule la suma del producto de la frecuencia de cada intervalo y el punto medio. ∑em

6. Distorsión y media, mediana y moda
Considere el siguiente conjunto de datos.
4; 5; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 10
Este conjunto de datos se puede representar mediante el siguiente histograma. Cada intervalo tiene un ancho de uno y cada valor se sitúa en el centro de un intervalo.
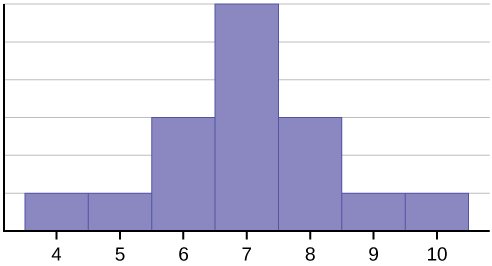
El histograma muestra una distribución simétrica de los datos. Una distribución es simétrica si se puede trazar una línea vertical en algún punto del histograma de manera que la forma a la izquierda y a la derecha de la línea vertical sean imágenes una espejo de la otra. La media, la mediana y la moda son siete para estos datos. En una distribución perfectamente simétrica, la media y la mediana son iguales. Este ejemplo tiene una moda (unimodal), y la moda es la misma que la media y la mediana. En una distribución simétrica que tiene dos modas (bimodal), las dos modas serían diferentes de la media y la mediana.
El histograma de los datos: 4; 5; 6; 6; 6; 7; 7; 7; 7; 8 (que se muestra en la siguiente figura) no es simétrico. El lado derecho parece “cortado” en comparación con el lado izquierdo. Una distribución de este tipo se denomina distorsionada a la izquierda porque se desplaza hacia la izquierda.
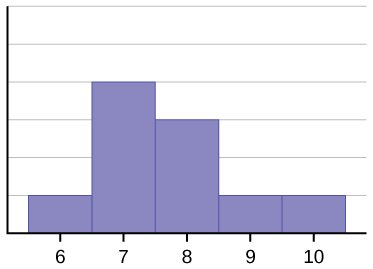
La media es 7,7, la mediana es 7,5 y la moda es siete. De las tres estadísticas, la media es la mayor, mientras que la moda es la menor. De nuevo, la media es la que más refleja la distorsión.
Para resumir, generalmente si la distribución de los datos está distorsionada a la izquierda, la media es menor que la mediana, que suele ser menor que la moda. Si la distribución de los datos está distorsionada a la derecha, la moda suele ser menor que la mediana, que es menor que la media.
La distorsión y la simetría son importantes cuando hablemos de distribuciones de probabilidad en capítulos posteriores.
Fuente y licenciamiento
- OpenStax (2022). Introducción a la estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0