Introducción
Probablemente te estés preguntando: “¿Cuándo y dónde voy a utilizar la estadística?”. Si lees cualquier periódico, vez la televisión o utiliza internet, verás información estadística. Hay estadísticas sobre delincuencia, deportes, educación, política y bienes raíces. Normalmente, cuando lees un artículo de periódico o vez un programa de noticias de televisión te da una información de muestra. Con esta información, puedes tomar una decisión sobre la corrección de una declaración, afirmación o “hecho”. Los métodos estadísticos pueden ayudarte a hacer una “mejor estimación”.
Como sin duda recibirás información estadística en algún momento de tu vida, necesitas conocer algunas técnicas para analizar la información de forma reflexiva. Piensa en la compra de una casa o en la gestión de un presupuesto. Piensa en la profesión que has elegido. Economía, Negocios, Psicología, Educación, Biología, Derecho, Informática, Política y Desarrollo de la Primera Infancia son campos de conocimiento que requieren, al menos, un curso de Estadística.

Contenidos temáticos
- Definiciones de estadística, probabilidad y términos clave
- Términos clave
Desarrollo del tema
1. Definiciones de estadística, probabilidad y términos clave
La ciencia de la estadística se ocupa de la recopilación, del análisis, de la interpretación y de la presentación de datos. Vemos y utilizamos datos en nuestra vida cotidiana.
La organización y el resumen de los datos se denominan Estadística Descriptiva. Dos formas de resumir los datos son la elaboración de gráficos y el uso de números (por ejemplo, hallar un promedio). Después de haber estudiado la probabilidad y las distribuciones de probabilidad, utilizarás métodos formales para sacar conclusiones de los datos “buenos”. Los métodos formales se denominan Estadística Inferencial. La inferencia estadística utiliza la probabilidad para determinar el grado de confianza que podemos tener de que nuestras conclusiones son correctas.
La interpretación eficaz de los datos (inferencia) se basa en buenos procedimientos de producción de datos y en examinarlos de forma reflexiva. Se encontrará con lo que le parecerá un exceso de fórmulas matemáticas para interpretar los datos. La meta de la Estadística no es realizar numerosos cálculos con las fórmulas, sino comprender los datos. Los cálculos se pueden hacer con una calculadora o una computadora. La comprensión debe venir de usted. Si puede comprender a fondo los fundamentos de la Estadística, podrá tener más confianza en las decisiones que tome en la vida.
Probabilidad
La probabilidad es una herramienta matemática utilizada para estudiar el azar. Se trata de la oportunidad (la posibilidad) de que se produzca un evento. Por ejemplo, si se lanza una moneda imparcial cuatro veces, los resultados no pueden ser dos caras y dos cruces. Sin embargo, si se lanza la misma moneda 4.000 veces, los resultados se aproximarán a mitad cara y mitad cruz. La probabilidad teórica esperada de salir cara en cualquier lanzamiento es:
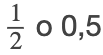
Aunque los resultados de unas pocas repeticiones son inciertos, existe un patrón regular de resultados cuando hay muchas repeticiones. Tras leer sobre el estadístico inglés Karl Pearson, que lanzó una moneda 24.000 veces con un resultado de 12.012 caras, uno de los autores lanzó una moneda 2.000 veces. Los resultados fueron 996 caras. La fracción
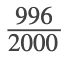
Es igual a 0,498, que está muy cerca de 0,5, la probabilidad esperada. La teoría de la probabilidad comenzó con el estudio de los juegos de azar, como el póquer. Las predicciones adoptan la forma de probabilidades. Para predecir la probabilidad de que se produzca un terremoto, de que llueva o de que obtenga una A en esta lección utilizamos las probabilidades. Los médicos utilizan la probabilidad para determinar la posibilidad de que una vacuna provoque la enfermedad que se supone que debe prevenir. Un agente de bolsa utiliza la probabilidad para determinar la tasa de rendimiento de las inversiones de un cliente. Puedes utilizar la probabilidad para decidir si compras un billete de lotería o no. En tu estudio de la Estadística, utilizarás el poder de las Matemáticas a través de cálculos de probabilidad para analizar e interpretar tus datos.
Términos clave
En estadística, generalmente queremos estudiar una población. Se puede pensar en una población como un conjunto de personas, cosas u objetos en estudio. Para estudiar la población seleccionamos una muestra. La idea del muestreo es seleccionar una porción (o subconjunto) de la población mayor y estudiar esa porción (la muestra) para obtener información sobre la población. Los datos son el resultado de un muestreo de una población.
Como se necesita mucho tiempo y dinero para examinar toda una población, el muestreo es una técnica muy práctica. Si deseas calcular el promedio general de calificaciones de tu escuela, tendría sentido seleccionar una muestra de estudiantes que asisten a la escuela. Los datos recopilados de la muestra serían los promedios de las calificaciones de los estudiantes. En las elecciones presidenciales se toman muestras de sondeos de opinión de 1.000 a 2.000 personas. Se supone que el sondeo de opinión representa el punto de vista de las personas de todo el país. Los fabricantes de bebidas carbonatadas en lata toman muestras para determinar si una lata de 16 onzas contiene 16 onzas de bebida carbonatada.
A partir de los datos de la muestra podemos calcular un estadístico. Un estadístico es un número que representa una propiedad de la muestra. Por ejemplo, si consideramos que una clase de Matemáticas es una muestra de la población de todas las clases de Matemáticas, el número promedio de puntos obtenidos por los estudiantes de esa clase de Matemáticas al final del trimestre es un ejemplo de un estadístico. El estadístico es una estimación de un parámetro de población. Un parámetro es una característica numérica de toda la población que puede estimarse mediante un estadístico. Dado que consideramos que todas las clases de Matemáticas son la población, el número promedio de puntos obtenidos por estudiante en todas las clases de Matemáticas es un ejemplo de parámetro.
Una de las principales preocupaciones en el campo de la Estadística es la precisión con la que un estadístico estima un parámetro. La precisión depende realmente de lo bien que la muestra represente a la población. La muestra debe contener las características de la población para ser una muestra representativa. En la Estadística Inferencial nos interesa tanto el estadístico de la muestra como el parámetro de la población.
Una variable, generalmente anotada con letras mayúsculas como X e Y, es una característica o medida que puede determinarse para cada miembro de una población. Las variables pueden ser numéricas o categóricas. Las variables numéricas toman valores con unidades iguales, como el peso en libras y el tiempo en horas. Las variables categóricas sitúan a la persona o cosa en una categoría. Si suponemos que X equivale al número de puntos obtenidos por un estudiante de Matemáticas al final de un trimestre, entonces X es una variable numérica. Si suponemos que Y es la afiliación de una persona a un partido, entonces algunos ejemplos de Y incluyen republicano, demócrata e independiente. Y es una variable categórica. Podríamos hacer algunos cálculos con valores de X (calcular el promedio de puntos obtenidos, por ejemplo), pero no tiene sentido hacer cálculos con valores de Y (calcular un promedio de afiliación a un partido no tiene sentido).
Los datos son los valores reales de la variable, pueden ser números o palabras, el dato es un valor único. Dos palabras que aparecen a menudo en estadística son media y proporción. Si presenta tres exámenes de sus clases de Matemáticas y obtiene calificaciones de 86, 75 y 92, calcularía su calificación media sumando las tres calificaciones de los exámenes y dividiéndolas entre tres (su calificación media sería 84,3 con un decimal).
Si en su clase de Matemáticas hay 40 estudiantes y 22 son hombres y 18 son mujeres, entonces la proporción de estudiantes hombres es:


::Para saber más::
Las palabras “media” y “promedio” suelen utilizarse indistintamente. La sustitución de una palabra por otra es una práctica habitual. El término técnico es “media aritmética” y “promedio” es técnicamente un lugar central. Sin embargo, en la práctica, entre los no estadísticos, se suele aceptar “promedio” por “media aritmética”.
Ejemplo para determinar los términos clave:
Determinar a qué se refieren los términos clave en el siguiente estudio. Queremos saber la cantidad promedio (media) de dinero que gastan los estudiantes de primer año del ABC College en material escolar que no incluya libros. Encuestamos al azar a 100 estudiantes de primer año del ABC College. Tres de esos estudiantes gastaron 150, 200 y 225 dólares, respectivamente.
Solución
A. La población está formada por todos los estudiantes de primer año que asisten al ABC College este trimestre.
B. La muestra podría ser todos los estudiantes inscritos en una sección de un curso de Estadística para principiantes en el ABC College (aunque esta muestra podría no representar a toda la población).
C. El parámetro es la cantidad promedio (media) de dinero (sin libros) que gastan los estudiantes de primer año del ABC College este trimestre.
D. El estadístico es la cantidad promedio de dinero gastado (sin libros) por los estudiantes de primer año en la muestra.
E. La variable podría ser la cantidad de dinero gastado (sin libros) por un estudiante de primer año. Supongamos que X = la cantidad de dinero gastado (sin libros) por un estudiante de primer año que asiste al ABC College.
F. Los datos son los montos en dólares gastados por los estudiantes de primer año. Los datos son, por ejemplo, 150, 200 y 225 dólares.
2. Datos, muestreo y variación de datos y muestreo
Los datos pueden proceder de una población o de una muestra. Letras minúsculas como 𝑥 o 𝑦 se utilizan generalmente para representar valores de datos. La mayoría de los datos se pueden clasificar en las siguientes categorías:
- Cualitativa
- Cuantitativa
Los datos cualitativos son el resultado de categorizar o describir los atributos de una población. Los datos cualitativos también suelen denominarse datos categóricos. El color del pelo, el tipo de sangre, el grupo étnico, el automóvil que conduce una persona y la calle en la que vive son ejemplos de datos cualitativos. Los datos cualitativos suelen describirse con palabras o letras. Por ejemplo, el color del cabello puede ser negro, castaño oscuro, castaño claro, rubio, gris o rojo. El tipo de sangre puede ser AB+, O– o B+. Los investigadores suelen preferir los datos cuantitativos a los cualitativos porque se prestan más al análisis matemático. Por ejemplo, no tiene sentido hallar un color de cabello o un tipo de sangre promedio.
Los datos cuantitativos son siempre números y son el resultado de contar o medir los atributos de una población. Por ejemplo: la cantidad de dinero, la frecuencia del pulso, el peso, el número de personas que viven en su ciudad y el número de estudiantes que cursan Estadística son ejemplos de datos cuantitativos. Los datos cuantitativos pueden ser discretos o continuos.
Todos los datos que son el resultado de contar se denominan datos discretos cuantitativos. Estos datos solo adoptan ciertos valores numéricos. Si cuenta el número de llamadas telefónicas que recibe cada día de la semana, puede obtener valores como cero, uno, dos o tres.
Los datos que no solo se componen de números para contar, sino que pueden incluir fracciones, decimales o números irracionales, se denominan datos cuantitativos continuos. Los datos continuos suelen ser el resultado de mediciones como longitudes, pesos o tiempos. Una lista de la duración en minutos de todas las llamadas telefónicas que realiza en una semana, con números como 2,4; 7,5; u 11,0, sería un dato cuantitativo continuo.
Ejemplo:
Va al supermercado y compra tres latas de sopa (19 onzas de sopa de tomate, 14,1 onzas de lentejas y 19 onzas de boda italiana), dos paquetes de frutos secos (nueces y cacahuetes), cuatro tipos de vegetales diferentes (brócoli, coliflor, espinacas y zanahorias) y dos postres (16 onzas de helado de pistacho y 32 onzas de galletas de chocolate).
Nombre los conjuntos de datos que son cuantitativos discretos, cuantitativos continuos y cualitativos.
Solución:
Una posible solución:
- Las tres latas de sopa, los dos paquetes de frutos secos, las cuatro clases de vegetales y los dos postres son datos cuantitativos discretos porque usted los cuenta.
- Los pesos de las sopas (19 onzas, 14,1 onzas y 19 onzas) son datos cuantitativos continuos porque mide los pesos con la mayor precisión posible.
- Los tipos de sopas, frutos secos, vegetales y postres son datos cualitativos porque son categóricos.
Discusión de datos cualitativos
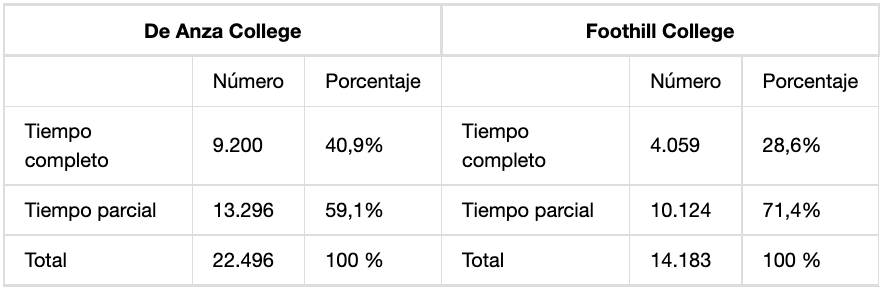
A continuación se muestran tablas que comparan el número de estudiantes a tiempo parcial y a tiempo completo en De Anza College y Foothill College inscritos para el trimestre de primavera de 2010. Las tablas muestran recuentos (frecuencias) y porcentajes o proporciones (frecuencias relativas). Las columnas de porcentajes facilitan la comparación de las mismas categorías en los institutos universitarios. Suele ser útil mostrar porcentajes junto con números, pero es especialmente importante cuando se comparan conjuntos de datos que no tienen los mismos totales, como las inscripciones totales de ambos institutos universitarios en este ejemplo. Observe que el porcentaje de estudiantes a tiempo parcial del Foothill College es mucho mayor que el del De Anza College.
Las tablas son una buena forma de organizar y mostrar datos. Pero los gráficos pueden ser aun más útiles para entender los datos. No hay reglas estrictas en cuanto a los gráficos que hay que utilizar. Dos gráficos que se utilizan para mostrar datos cualitativos son los gráficos circulares y los de barras.
- En un gráfico circular las categorías de datos se representan mediante cuñas en un círculo y su tamaño es proporcional al porcentaje de personas de cada categoría.
- En un gráfico de barras la longitud de la barra para cada categoría es proporcional al número o porcentaje de personas en cada categoría. Las barras pueden ser verticales u horizontales.
- Un diagrama de Pareto está formado por barras que se ordenan por el tamaño de la categoría (de mayor a menor).
Observa la Figura 1 y la Figura 2 y determina qué gráfico (circular o de barras) crees que muestra mejor las comparaciones. Para revisar las imágenes desliza las flechas para ver las diferencias de los gráficos:
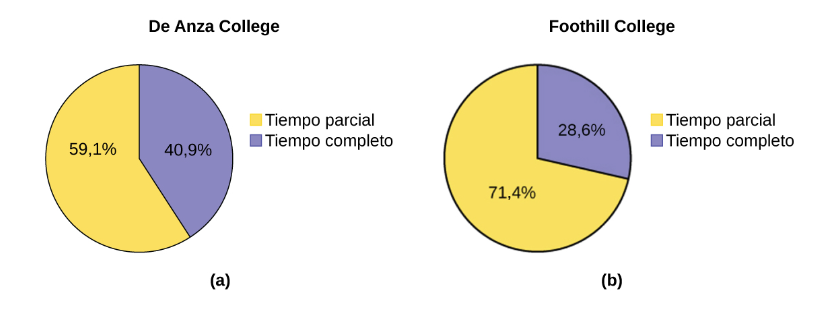
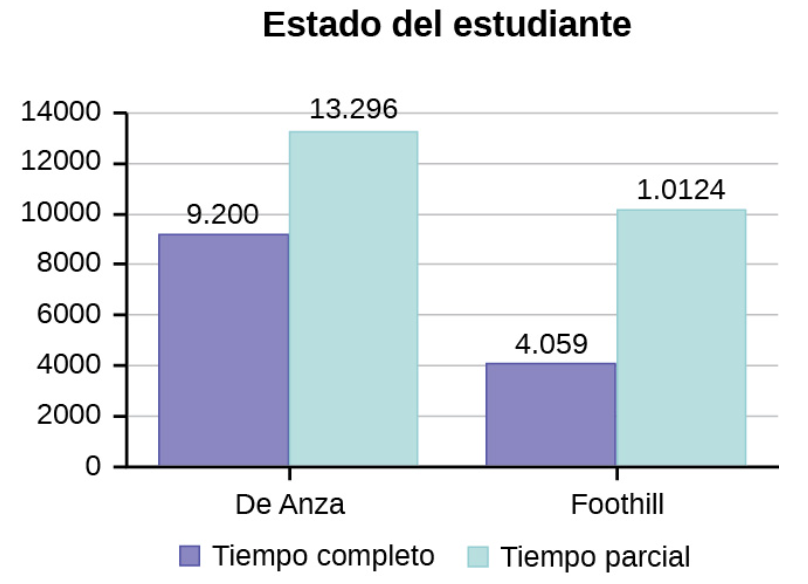
Es una buena idea observar una variedad de gráficos para ver cuál es el más útil para mostrar los datos. Según los datos y el contexto, podemos elegir el “mejor” gráfico. Nuestra elección también depende del uso que hagamos de los datos.
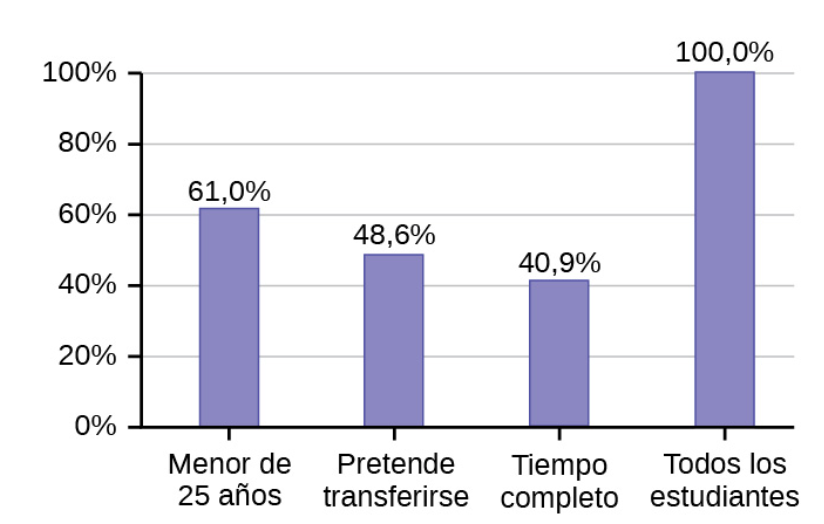
Porcentajes que suman más (o menos) que el 100 %
A veces, los porcentajes suman más del 100 % (o menos del 100 %). En el gráfico, los porcentajes suman más del 100 % porque los estudiantes pueden estar en más de una categoría. Un gráfico de barras es apropiado para comparar el tamaño relativo de las categorías. No se puede utilizar un gráfico circular. Tampoco podía utilizarse si los porcentajes sumaban menos del 100 %.
| Característica/Categoría | Porcentaje |
|---|---|
| Estudiantes a tiempo completo | 40,9% |
| Estudiantes que pretenden transferirse a una institución educativa de 4 años | 48,6% |
| Estudiantes menores de 25 años | 61,0% |
| TOTAL | 150,5% |
Ejemplo de representación gráfica
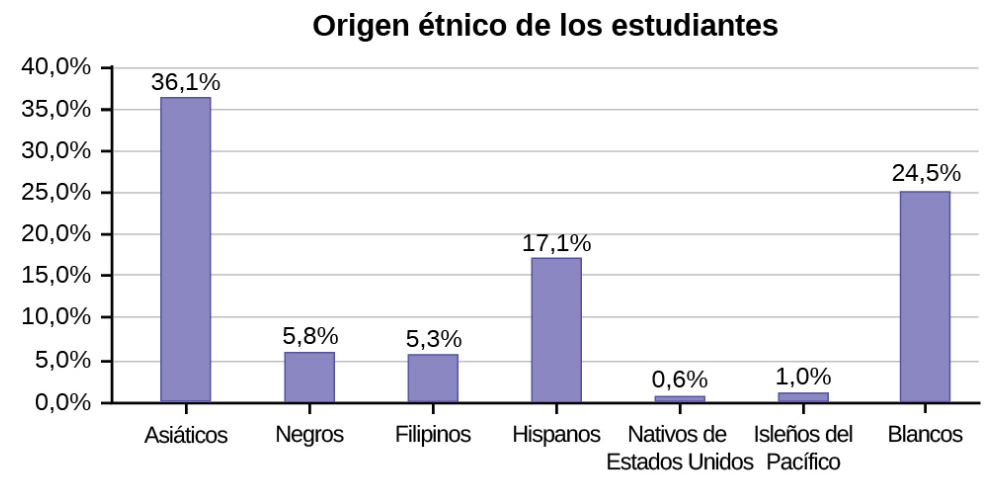
Omisión de categorías/falta de datos
La tabla muestra el origen étnico de los estudiantes pero falta la categoría “otros/desconocidos”. En esta categoría se ubican las personas que no se consideraron incluidas en ninguna de las categorías étnicas o que se negaron a responder. Observa que las frecuencias no suman el número total de estudiantes. En esta situación, se creo un gráfico de barras y no un gráfico circular.
| Frecuencia | Porcentaje | |
|---|---|---|
| Asiáticos | 8.794 | 36,1% |
| Negros | 1.412 | 5,8% |
| Filipinos | 1.298 | 5,3% |
| Hispanos | 4.180 | 17,1% |
| Nativos de Estados Unidos 146 0,6 % | 146 | 0,6 % |
| Isleños del Pacífico | 236 | 1,0% |
| Blancos | 5.978 | 24,5% |
| TOTAL | 22.044 de 24.382 | 90,4 % del 100 % |
Ejemplo de representación gráfica
Muestreo
Recopilar información sobre toda una población suele ser demasiado costoso o prácticamente imposible. En cambio, utilizamos una muestra de la población. Una muestra debe tener las mismas características que la población que representa. La mayoría de los estadísticos utilizan varios métodos de muestreo aleatorio para intentar alcanzar esta meta. En esta sección se describen algunos de los métodos más comunes. Existen varios métodos de muestreo aleatorio. En cada forma de muestreo aleatorio, cada miembro de una población tiene inicialmente la misma probabilidad de que lo seleccionen para la muestra. Cada método tiene sus pros y sus contras. El método más fácil de describir se llama muestra aleatoria simple. Cualquier grupo de n personas tiene la misma probabilidad de que lo seleccionen que cualquier otro grupo de n personas si se utiliza la técnica de muestreo aleatorio simple. En otras palabras, cada muestra del mismo tamaño tiene la misma probabilidad de que la seleccionen. Por ejemplo, supongamos que Lisa quiere formar un grupo de estudio de cuatro personas (ella y otras tres) de su clase de precálculo, que tiene 31 miembros sin incluir a Lisa. Para elegir una muestra aleatoria simple de tamaño tres entre los demás miembros de su clase, Lisa podría poner los 31 nombres en un sombrero, agitar el sombrero, cerrar los ojos y elegir tres nombres. Una forma más tecnológica es que Lisa enumere primero los apellidos de los miembros de su clase junto con un número de dos dígitos, como en la Tabla 4:
| ID | Nombre | ID | Nombre | ID | Nombre |
|---|---|---|---|---|---|
| 00 | Anselmo | 11 | King | 21 | Roquero |
| 01 | Bautista | 12 | Legeny | 22 | Roth |
| 02 | Bayani | 13 | Lundquist | 23 | Rowell |
| 03 | Cheng | 14 | Macierz | 24 | Salangsang |
| 04 | Cuarismo | 15 | Motogawa | 25 | Slade |
| 05 | Cuningham | 16 | Okimoto | 26 | Stratcher |
| 06 | Fontecha | 17 | Patel | 27 | Tallai |
| 07 | Hong | 18 | Price | 28 | Tran |
| 08 | Hoobler | 19 | Quizon | 29 | Wai |
| 09 | Jiao | 20 | Reyes | 30 | Madera |
| 10 | Khan | Reyes |
Lisa puede utilizar una tabla de números aleatorios (que se encuentra en muchos libros de estadística y manuales de matemáticas), una calculadora o una computadora para generar números aleatorios. Para este ejemplo, supongamos que Lisa elige generar números aleatorios con una calculadora. Los números generados son los siguientes:
0,94360; 0,99832; 0,14669; 0,51470; 0,40581; 0,73381; 0,04399
Lisa lee grupos de dos dígitos hasta que haya elegido tres miembros de la clase (es decir, lee 0,94360 como los grupos 94, 43, 36, 60). Cada número aleatorio solo puede aportar un miembro de la clase. De ser necesario, Lisa podría haber generado más números aleatorios.
Los números aleatorios 0,94360 y 0,99832 no contienen números de dos dígitos adecuados. Sin embargo, el tercer número aleatorio, 0,14669, contiene 14 (el cuarto número aleatorio también contiene 14), el quinto número aleatorio contiene 05 y el séptimo número aleatorio contiene 04. El número de dos dígitos 14 corresponde a Macierz, el 05 a Cuningham y el 04 a Cuarismo. Aparte de ella, el grupo de Lisa estará formado por Marcierz, Cuningham y Cuarismo.
Además del muestreo aleatorio simple, existen otras formas de muestreo que implican un proceso de azar para obtener la muestra. Otros métodos de muestreo aleatorio bien conocidos son la muestra estratificada, la muestra por conglomerados y la muestra sistemática.
Para seleccionar una muestra estratificada, hay que dividir la población en grupos llamados estratos y, a continuación, tomar un número proporcional de cada estrato. Por ejemplo, podría estratificar (agrupar) la población de su instituto universitario por departamentos y luego seleccionar una muestra aleatoria simple proporcional de cada estrato (cada departamento) para obtener una muestra aleatoria estratificada. Para seleccionar una muestra aleatoria simple de cada departamento, numere cada miembro del primer departamento, numere cada miembro del segundo departamento y haga lo mismo con los departamentos restantes. Luego, utilice un muestreo aleatorio simple para seleccionar números proporcionales del primer departamento y haga lo mismo con cada uno de los departamentos restantes. Esos números seleccionados del primer departamento y del segundo departamento, y así sucesivamente, representan los miembros que componen la muestra estratificada.
Para seleccionar una muestra por conglomerados hay que dividir la población en conglomerados (grupos) y luego seleccionar al azar algunos de los conglomerados. Todos los miembros de estos grupos están en la muestra por conglomerados. Por ejemplo, si toma una muestra aleatoria de cuatro departamentos de la población de su instituto universitario, los cuatro departamentos constituyen la muestra por conglomerados. Divida el profesorado de su instituto universitario por departamento. Los departamentos son los conglomerados. Numere cada departamento y, a continuación, elija cuatro números diferentes mediante un muestreo aleatorio simple. Todos los miembros de los cuatro departamentos con esos números son la muestra de conglomerado.
Para seleccionar una muestra sistemática, seleccione al azar un punto de partida y tome cada n.ª (enésima) pieza de datos de una lista de la población. Por ejemplo, supongamos que tiene que hacer una encuesta telefónica. Su directorio telefónico contiene 20.000 listas de residencias. Debe seleccionar 400 nombres para la muestra. Numere la población de 1 a 20.000 y luego utilice una muestra aleatoria simple para seleccionar un número que represente el primer nombre de la muestra. Luego, elija cada quincuagésimo nombre hasta que tenga un total de 400 nombres (puede que tenga que volver al principio de su lista de teléfonos). El muestreo sistemático se elige con frecuencia porque es un método sencillo.
Un tipo de muestreo que no es aleatorio es el muestreo de conveniencia. El muestreo de conveniencia implica el uso de resultados que están fácilmente disponibles. Por ejemplo, una tienda de softwares realiza un estudio de mercadeo mediante entrevistas con los clientes potenciales que se encuentran en la tienda mirando softwares disponibles. Los resultados del muestreo de conveniencia pueden ser muy buenos en algunos casos y muy sesgados (favorecer ciertos resultados) en otros.
El muestreo de datos debe hacerse con mucho cuidado. Recolectar datos sin cuidado puede causar resultados devastadores. Las encuestas enviadas por correo a los hogares y luego devueltas pueden estar muy sesgadas (pueden favorecer a un determinado grupo). Es mejor que la persona que realiza la encuesta seleccione la muestra de encuestados.
El muestreo aleatorio verdadero se realiza con reemplazo. Es decir, una vez que se selecciona un miembro, ese miembro vuelve a la población y, por tanto, lo pueden escoger más de una vez. Sin embargo, por razones prácticas, en la mayoría de las poblaciones el muestreo aleatorio simple se realiza sin reemplazo. Las encuestas suelen hacerse sin reemplazo. Es decir, un miembro de la población solo lo pueden seleccionar una vez. La mayoría de las muestras se toman de poblaciones grandes y la muestra tiende a ser pequeña en comparación con la población. En este caso, el muestreo sin reemplazo es, aproximadamente, igual al muestreo con reemplazo, ya que la probabilidad de seleccionar a la misma persona más de una vez con reemplazo es muy baja.
En una población universitaria de 10.000 personas, supongamos que se quiere seleccionar una muestra de 1.000 al azar para una encuesta. Para cualquier muestra particular de 1.000, si se hace un muestreo con reemplazo,
- la probabilidad de seleccionar la primera persona es de 1.000 entre 10.000 (0,1000);
- la probabilidad de seleccionar una segunda persona diferente para esta muestra es de 999 entre 10.000 (0,0999);
- la probabilidad de volver a seleccionar a la misma persona es de 1 entre 10.000 (muy baja).
Si se trata de un muestreo sin reemplazo,
- la probabilidad de seleccionar la primera persona para cualquier muestra específica es de 1.000 entre 10.000 (0,1000);
- la probabilidad de seleccionar una segunda persona diferente es de 999 entre 9.999 (0,0999);
- no se sustituye la primera persona antes de seleccionar la siguiente.
Compare las fracciones 999/10.000 y 999/9.999. Para lograr más exactitud, lleve las respuestas decimales a cuatro cifras. Con cuatro decimales, estos números son equivalentes (0,0999).
El muestreo sin reemplazo en vez del muestreo con reemplazo se convierte en una cuestión matemática solo cuando la población es pequeña. Por ejemplo, si la población es de 25 personas, la muestra es de diez y se realiza un muestreo con reemplazo para cualquier muestra particular, entonces la probabilidad de seleccionar la primera persona es de diez entre 25, y la probabilidad de seleccionar una segunda persona diferente es de nueve entre 25 (se reemplaza la primera persona).
Si se hace una muestra sin reemplazo, la probabilidad de seleccionar la primera persona es de diez entre 25, y la probabilidad de seleccionar la segunda persona (que es diferente) es de nueve entre 24 (no se reemplaza la primera persona).
Compare las fracciones 9/25 y 9/24. Con cuatro decimales, 9/25 = 0,3600 y 9/24 = 0,3750. Con cuatro decimales, estos números no son equivalentes.
Al analizar los datos, es importante tener en cuenta los errores de muestreo y los errores ajenos al muestreo. El propio proceso de muestreo provoca errores de muestreo. Por ejemplo, la muestra puede no ser lo suficientemente grande. Los factores no relacionados con el proceso de muestreo provocan errores ajenos al muestreo. Un dispositivo de recuento defectuoso puede causar un error ajeno al muestreo.
En realidad, una muestra nunca será exactamente representativa de la población, por lo que siempre habrá algún error de muestreo. Por regla general, cuanto mayor sea la muestra, menor será el error de muestreo.
En estadística, se crea un sesgo de muestreo cuando se recopila una muestra de una población y algunos de sus miembros no tienen la misma probabilidad de que los seleccionen que otros (recuerde que cada miembro de la población debe tener la misma probabilidad de que lo seleccionen). Cuando se produce un sesgo de muestreo, se pueden extraer conclusiones incorrectas sobre la población que se está estudiando.
Evaluación crítica
Tenemos que evaluar los estudios estadísticos que leemos de forma crítica y analizarlos antes de aceptar sus resultados. Los problemas más comunes que hay que tener en cuenta son:
- Problemas con las muestras: una muestra debe ser representativa de la población. Una muestra que no es representativa de la población está sesgada. Las muestras sesgadas que no son representativas de la población dan resultados inexactos y no válidos.
- Muestras autoseleccionadas: las respuestas de las personas que deciden responder, cómo las encuestas telefónicas, suelen ser poco fiables.
- Problemas de tamaño de la muestra: las muestras demasiado pequeñas pueden ser poco fiables. Si es posible, las muestras más grandes son mejores. En algunas situaciones, es inevitable contar con muestras pequeñas y, aun así, se pueden usar para sacar conclusiones. Ejemplos: pruebas de choques de automóviles o pruebas médicas para detectar condiciones poco comunes.
- Influencia indebida: recopilar datos o hacer preguntas de forma que influyan en la respuesta.
- Falta de respuesta o negativa del sujeto a participar: las respuestas recogidas pueden dejar de ser representativas de la población. A menudo, personas con fuertes opiniones positivas o negativas pueden responder las encuestas, lo que puede afectar los resultados.
- Causalidad: una relación entre dos variables no significa que una cause la otra. Pueden estar relacionadas (correlacionadas) debido a su relación a través de una variable diferente.
- Estudios autofinanciados o de interés propio: estudio realizado por una persona u organización para respaldar su afirmación. ¿El estudio es imparcial? Lea atentamente el estudio para evaluar el trabajo. No asuma automáticamente que el estudio es bueno, pero tampoco asuma automáticamente qué es deficiente. Valórelo por sus méritos y el trabajo realizado.
- Uso engañoso de datos: gráficos mal presentados, datos incompletos o falta de contexto.
- Confusión: cuando los efectos de múltiples factores sobre una respuesta no se pueden separar. Los factores de confusión dificultan o impiden sacar conclusiones válidas sobre el efecto de cada uno de ellos.
Ejemplo:
Se realiza un estudio para determinar la matrícula promedio que los estudiantes de educación superior del estado de San José pagan por semestre. En las siguientes muestras se pregunta a cada estudiante cuánto pagó de matrícula en el semestre de otoño. ¿Cuál es el tipo de muestreo en cada caso?
a. Se toma una muestra de 100 estudiantes de educación superior del estado de San José y se organizan los nombres de los estudiantes por clasificación (primero y segundo años, júnior y sénior) y se seleccionan 25 estudiantes de cada uno.
b. Se utiliza un generador de números aleatorios para seleccionar un estudiante de la lista alfabética de todos los estudiantes de pregrado en el semestre de otoño. A partir de ese estudiante, se elige cada 50 estudiantes hasta incluir 75 en la muestra.
c. Se utiliza un método completamente aleatorio para seleccionar 75 estudiantes. Cada estudiante de educación superior del semestre de otoño tiene la misma probabilidad de que lo seleccionen en cualquier fase del proceso de muestreo.
d. Los de primero, segundo, júnior y sénior años están numerados como uno, dos, tres y cuatro, respectivamente. Se utiliza un generador de números aleatorios para seleccionar dos de esos años. Todos los estudiantes de esos dos años están en la muestra.
e. Se le pide a un asistente administrativo que se sitúe un miércoles frente a la biblioteca y les pregunte a los 100 primeros estudiantes de educación superior que calculen cuánto han pagado de matrícula en el semestre de otoño. Esos 100 estudiantes son la muestra.
Solución:
a. estratificado; b. sistemático; c. aleatoria simple; d. por conglomerados; e. de conveniencia
Variación de los datos
La variación está presente en cualquier conjunto de datos. Por ejemplo, las latas de bebida de 16 onzas pueden contener más o menos de 16 onzas de líquido. En un estudio, se midieron ocho latas de 16 onzas y produjeron la siguiente cantidad (en onzas) de bebida:
15,8; 16,1; 15,2; 14,8; 15,8; 15,9; 16,0; 15,5
Las medidas de la cantidad de bebida en una lata de 16 onzas pueden variar porque diferentes personas hacen las mediciones o porque no se puso la cantidad exacta, 16 onzas de líquido, en las latas. Los fabricantes realizan regularmente pruebas para determinar si la cantidad de bebida en una lata de 16 onzas está dentro del rango deseado.
Tenga en cuenta que, al tomar los datos, estos pueden variar en cierta medida con respecto a los datos que otra persona está tomando para el mismo fin. Esto es completamente natural. Sin embargo, si dos o más de ustedes toman los mismos datos y obtienen resultados muy diferentes, es hora de que usted y los demás reevalúen sus métodos de toma de datos y su exactitud.
Variación en las muestras
Ya se ha mencionado anteriormente que dos o más muestras de la misma población, tomadas al azar y que se aproximen a las mismas características de la población serán probablemente diferentes entre sí. Supongamos que Doreen y Jung deciden estudiar la cantidad promedio de tiempo que los estudiantes de su instituto universitario duermen cada noche. Doreen y Jung toman cada uno muestras de 500 estudiantes. Doreen utiliza el muestreo sistemático y Jung el muestreo por conglomerados. La muestra de Doreen será diferente a la de Jung. Aunque Doreen y Jung utilizaran el mismo método de muestreo, con toda probabilidad sus muestras serían diferentes. Sin embargo, ninguno de los dos estaría equivocado. Piensa en lo que contribuye a que las muestras de Doreen y Jung sean diferentes.
Si Doreen y Jung tomaran muestras más grandes (es decir, el número de valores de los datos se incrementa), los resultados de su muestra (la cantidad promedio de tiempo que duerme un estudiante) podrían estar más cerca del promedio real de la población. Pero aun así, sus muestras serían, con toda probabilidad, diferentes entre sí. Nunca se insistirá lo suficiente en esta variabilidad en las muestras.
Tamaño de la muestra
El tamaño de la muestra (a menudo llamado número de observaciones) es importante. Los ejemplos que ha visto en este libro hasta ahora han sido pequeños. Muestras de solo unos cientos de observaciones, o incluso más pequeñas, son suficientes para muchos propósitos. En los sondeos, las muestras que van de 1.200 a 1.500 observaciones se consideran suficientemente grandes y buenas si la encuesta es aleatoria y está bien hecha. Aprenderá por qué cuando estudies intervalos de confianza.
Ten en cuenta que muchas muestras grandes están sesgadas. Por ejemplo, las encuestas con llamadas están invariablemente sesgadas porque la gente decide responder o no.
Fuente y licenciamiento
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0