Contenidos temáticos
- Frecuencia, tablas de frecuencia y niveles de medición
- Diseño experimental y ética
Desarrollo del tema
1. Frecuencia, tablas de frecuencia y niveles de medición
Una vez que se tenga un conjunto de datos, se tendrán que organizar para poder analizar la frecuencia con la que aparece cada dato en el conjunto. Sin embargo, al calcular la frecuencia, es posible que se tengan que redondear las respuestas para que sean lo más precisas posible.
Respuestas y redondeo
Una forma sencilla de redondear las respuestas es llevar la respuesta final a un decimal más de los que aparecen en los datos originales. Redondea solo la respuesta final si es posible, no redondees los resultados intermedios. Si es necesario redondear los resultados intermedios, llévalos al menos al doble de decimales que la respuesta final. Por ejemplo, el promedio de las tres puntuaciones de un cuestionario que son cuatro, seis y nueve es 6,3, redondeada a la décima más cercana, porque los datos son números enteros. La mayoría de las respuestas se redondearán de esta manera.
No es necesario reducir la mayoría de las fracciones en especialmente en temas de probabilidad, el tema sobre la probabilidad, es más útil dejar las respuestas como fracciones no reducidas.
Niveles de medición
La forma de medir un conjunto de datos se denomina nivel de medición. Los procedimientos estadísticos correctos dependen de que el investigador esté familiarizado con los niveles de medición, no todas las operaciones estadísticas se pueden usar con todos los conjuntos de datos. Los datos se pueden clasificar en cuatro niveles de medición, son (de menor a mayor nivel):
- Nivel de escala nominal
- Nivel de escala ordinal
- Nivel de escala de intervalos
- Nivel de escala de cociente
Los datos que se miden mediante una escala nominal son cualitativos (categóricos). Categorías, colores, nombres, etiquetas y alimentos favoritos junto con las respuestas de sí o no son ejemplos de datos de nivel nominal. Los datos de escala nominal no están ordenados. Por ejemplo, intentar clasificar a las personas según su comida favorita no tiene ningún sentido. Poner la pizza en primer lugar y el sushi en segundo no tiene sentido.
Las compañías de teléfonos inteligentes son otro ejemplo de datos de escala nominal, los datos son los nombres de las compañías que fabrican teléfonos inteligentes, pero no hay un orden consensuado de estas marcas, aunque la gente pueda tener preferencias personales, los datos de escala nominal no se pueden usar en cálculos.
Los datos que se miden con una escala ordinal son similares a los datos de la escala nominal, pero hay una gran diferencia. Los datos de la escala ordinal se pueden ordenar, un ejemplo de datos de escala ordinal es una lista de los cinco mejores parques nacionales de Estados Unidos o los cinco principales parques nacionales de Estados Unidos se pueden clasificar del uno al cinco, pero no podemos medir las diferencias entre los datos.
Otro ejemplo de uso de la escala ordinal es una encuesta sobre un crucero en la que las respuestas son “excelente”, “bueno”, “satisfactorio” e “insatisfactorio”. Estas respuestas están ordenadas de la respuesta más deseada a la menos deseada. Pero las diferencias entre dos datos no se pueden medir, al igual que los datos de la escala nominal, los datos de la escala ordinal no se pueden usar en cálculos.
Los datos que se miden con la escala de intervalos son similares a los datos de nivel ordinal porque tienen un orden definido, pero hay una diferencia entre los datos, las diferencias entre los datos de la escala de intervalos se pueden medir aunque los datos no tengan un punto de partida.
Las escalas de temperatura como Celsius (C) y Fahrenheit (F) se miden utilizando la escala de intervalos. En ambas medidas de temperatura, 40° es igual a 100° menos 60°. Las diferencias tienen sentido, pero los 0 grados no porque, en ambas escalas, el 0 no es la temperatura mínima absoluta. Existen temperaturas como –10 °F y –15 °C que son más frías que el 0.
Los datos a nivel de intervalo pueden utilizarse en cálculos, pero no se puede hacer un tipo de comparación. 80 °C no es cuatro veces más caliente que 20 °C (ni 80 °F es cuatro veces más caliente que 20 °F). El cociente de 80 a 20 (o de cuatro a uno) no tiene sentido.
Los datos que se miden con la escala de cociente se encargan del problema de las proporciones y ofrecen más información. Los datos de la escala de cociente son como los datos de la escala de intervalos, pero tienen un punto 0 y se pueden calcular cocientes. Por ejemplo, las calificaciones de cuatro exámenes finales de Estadística de opción múltiple son 80, 68, 20 y 92 (sobre 100 puntos posibles). Los exámenes son calificados por máquina.
Los datos se pueden ordenar de menor a mayor: 20, 68, 80, 92.
Las diferencias entre los datos tienen un significado. La calificación de 92 es superior a la de 68 por 24 puntos. Se pueden calcular cocientes. La calificación más baja es 0. Así que 80 es cuatro veces 20. La calificación de 80 es cuatro veces mejor que la de 20.
Frecuencia
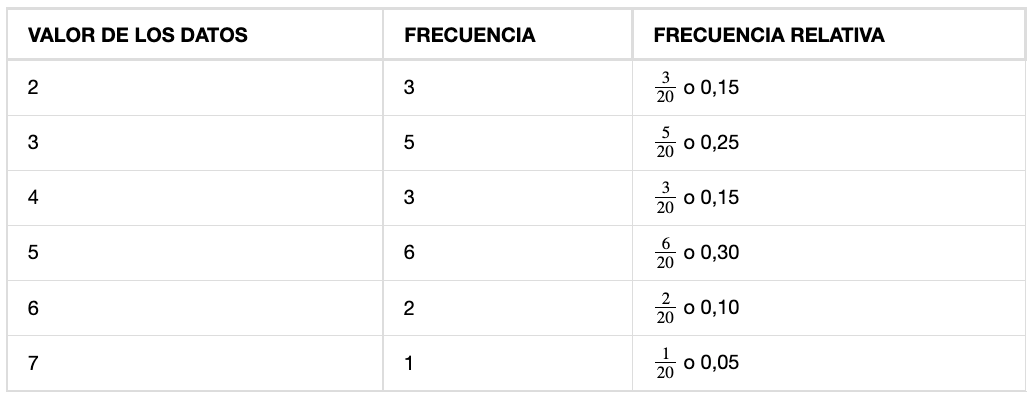
Se les preguntó a veinte estudiantes cuántas horas trabajaban al día, sus respuestas, en horas, son las siguientes: 5; 6; 3; 3; 2; 4; 7; 5; 2; 3; 5; 6; 5; 4; 4; 3; 5; 2; 5; 3.
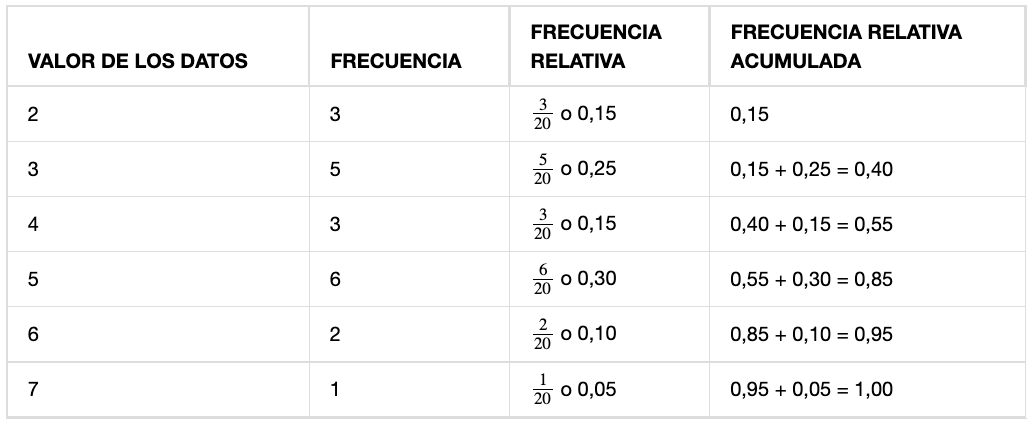
La Tabla 1 enumera los diferentes valores de los datos en orden ascendente y sus frecuencias.
| VALOR DE LOS DATOS | FRECUENCIA |
|---|---|
| 2 | 3 |
| 3 | 5 |
| 4 | 3 |
| 5 | 6 |
| 6 | 2 |
| 7 | 1 |
Una frecuencia es el número de veces que se produce un valor de los datos, según la Tabla 1. hay tres estudiantes que trabajan dos horas, cinco estudiantes que trabajan tres horas y así sucesivamente, la suma de los valores de la columna de frecuencia, 20, representa el número total de estudiantes incluidos en la muestra.
Una frecuencia relativa es el cociente (fracción o proporción) entre el número de veces que se produce un valor de los datos en el conjunto de todos los resultados y el número total de resultados, para hallar las frecuencias relativas, divida cada frecuencia entre el número total de estudiantes de la muestra, en este caso, 20. Las frecuencias relativas se pueden escribir como fracciones, porcentajes o decimales.
La suma de los valores de la columna de frecuencia relativa de la Tabla 2 es:
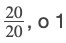
La frecuencia relativa acumulada es la acumulación de las frecuencias relativas anteriores. Para hallar las frecuencias relativas acumuladas se suman todas las frecuencias relativas anteriores a la frecuencia relativa de la fila actual, como se muestra en la Tabla 3.
La última entrada de la columna de frecuencia relativa acumulada es uno, lo que indica que se ha acumulado el cien por ciento de los datos. La Tabla 4 representa las alturas, en pulgadas, de una muestra de 100 hombres jugadores de fútbol semiprofesionales.
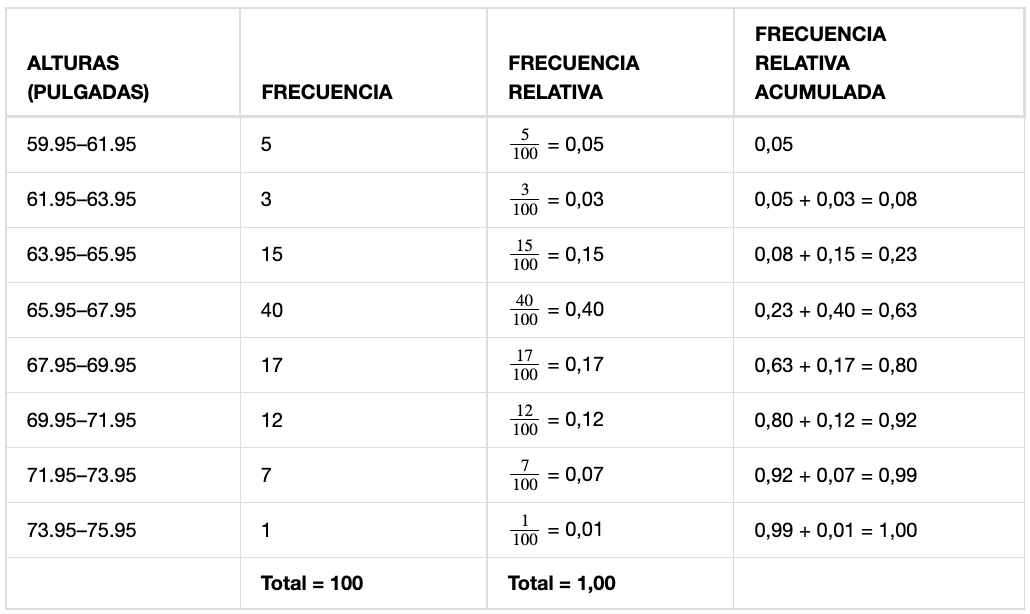
Los datos de esta tabla se han agrupado en los siguientes intervalos:
- de 59,95 a 61,95 pulgadas
- de 61,95 a 63,95 pulgadas
- de 63,95 a 65,95 pulgadas
- de 65,95 a 67,95 pulgadas
- de 67,95 a 69,95 pulgadas
- de 69,95 a 71,95 pulgadas
- de 71,95 a 73,95 pulgadas
- de 73,95 a 75,95 pulgadas
En esta muestra hay cinco jugadores cuyas alturas están dentro del intervalo de 59,95 a 61,95 pulgadas, tres dentro del intervalo de 61,95 a 63,95 pulgadas, 15 dentro del intervalo de 63,95 a 65,95 pulgadas, 40 dentro del intervalo de 65,95 a 67,95 pulgadas, 17 dentro del intervalo de 67,95 a 69,95 pulgadas, 12 jugadores dentro del intervalo de 69,95 a 71,95, siete dentro del intervalo de 71,95 a 73,95 y un jugador cuya altura está dentro del intervalo de 73,95 a 75,95. Todas las alturas caen entre los puntos finales de un intervalo y no en los puntos finales.
Ejemplo:
A partir de la Tabla 4, calcula el porcentaje de alturas que son inferiores a 65,95 pulgadas.
Solución
Si se observan la primera, la segunda y la tercera filas, las alturas son todas inferiores a 65,95 pulgadas. Hay 5 + 3 + 15 = 23 jugadores cuya altura es inferior a 65,95 pulgadas. El porcentaje de alturas inferiores a 65,95 pulgadas es entonces
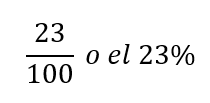
Este porcentaje es la entrada de frecuencia relativa acumulada en la tercera fila.
2. Diseño experimental y ética
¿La aspirina reduce el riesgo de infarto? ¿Una marca de abono es más eficaz para el cultivo de rosas que otra? ¿El cansancio es tan peligroso para un conductor como la influencia del alcohol? Este tipo de preguntas se responden con experimentos aleatorios. En este módulo aprenderá aspectos importantes del diseño experimental. Un diseño adecuado del estudio garantiza la obtención de datos fiables y precisos.
El propósito de un experimento es investigar la relación entre dos variables. Cuando una variable provoca un cambio en otra, llamamos a la primera variable la variable explicativa. La variable afectada se denomina variable de respuesta, en un experimento aleatorio, el investigador manipula los valores de la variable explicativa y mide los cambios resultantes en la variable de respuesta. Los diferentes valores de la variable explicativa se denominan tratamientos, una unidad experimental es un único objeto o persona que se va a medir.
Quieres investigar la eficacia de la vitamina E en la prevención de enfermedades, recluta a un grupo de sujetos y les pregunta si toman regularmente vitamina E. Observa que los sujetos que toman vitamina E, en promedio, presentan una salud mejor que quienes no la toman. ¿Esto prueba que la vitamina E es eficaz en la prevención de enfermedades? No es así, hay muchas diferencias entre los dos grupos comparados, además del consumo de vitamina E. Las personas que toman vitamina E con regularidad suelen tomar otras medidas para mejorar su salud: ejercicio, dieta, otros suplementos vitamínicos, elección de no fumar, etc. Cualquiera de estos factores podría estar influyendo en la salud, como se ha descrito, este estudio no demuestra que la vitamina E sea la clave para la prevención de enfermedades.
Las variables adicionales que pueden enturbiar un estudio se denominan variables ocultas, para demostrar que la variable explicativa provoca un cambio en la variable de respuesta, es necesario aislar la variable explicativa. La investigadora debe diseñar su experimento de forma que solo haya una diferencia entre los grupos que se comparan: los tratamientos previstos. Esto se consigue mediante la asignación aleatoria de unidades experimentales a grupos de tratamiento. Cuando los sujetos se asignan a los tratamientos de forma aleatoria, todas las variables ocultas potenciales se reparten por igual entre los grupos. En este punto, la única diferencia entre los grupos es la impuesta por el investigador. Los diferentes resultados medidos en la variable de respuesta, por tanto, deben ser una consecuencia directa de los diferentes tratamientos. De este modo, un experimento puede demostrar una conexión causa-efecto entre las variables explicativas y las de respuesta.
El poder de la sugestión puede tener una importante influencia en el resultado de un experimento. Los estudios han demostrado que la expectativa del participante en el estudio puede ser tan importante como el medicamento real. En un estudio sobre fármacos que mejoran el desempeño, los investigadores señalaron:
Los resultados mostraron que creer que se había tomado la sustancia provocaba tiempos de [desempeño] casi tan rápidos como los asociados al consumo del propio fármaco. Por el contrario, la toma del fármaco sin conocimiento no produjo un aumento significativo del desempeño.
Cuando la participación en un estudio provoca una respuesta física del participante, es difícil aislar los efectos de la variable explicativa. Para contrarrestar el poder de la sugestión, los investigadores reservaron un grupo de tratamiento como grupo de control. Este grupo recibe un tratamiento placebo, es decir, un tratamiento que no puede influir en la variable de respuesta. El grupo de control ayuda a los investigadores a equilibrar los efectos de estar en un experimento con los efectos de los tratamientos activos. Por supuesto, si tu participas en un estudio y sabes que estás recibiendo una píldora que no contiene ningún medicamento real, entonces el poder de la sugestión ya no es un factor, que un experimento aleatorio sea ciego preserva el poder de la sugestión. Cuando una persona participa en un estudio de investigación ciego, no sabe quién recibe el tratamiento activo y quién el placebo, un experimento doble ciego es aquel en el que tanto los sujetos como los investigadores que participan en él no conocen la información del fármaco.
Ética
El mal uso y la tergiversación generalizados de la información estadística suelen dar mala fama a este campo. Algunos dicen que “los números no mienten”, pero las personas que utilizan los números para apoyar sus afirmaciones a menudo lo hacen.
Una reciente investigación sobre el famoso psicólogo social Diederik Stapel ha llevado a la retractación de sus artículos en algunas de las principales revistas del mundo, como Journal of Experimental Social Psychology, Social Psychology, Basic and Applied Social Psychology, British Journal of Social Psychology y la revista Science. Diederik Stapel es un antiguo profesor de la Universidad de Tilburg (Países Bajos). En los últimos dos años, una amplia investigación en la que han participado tres universidades en las que ha trabajado Stapel ha concluido que el psicólogo es culpable de un fraude a escala colosal. Los datos falsificados contaminaron más de 55 artículos de su autoría y 10 tesis doctorales que supervisó.
Stapel no negó que su engaño estuviera motivado por la ambición. Pero me dijo que era más complicado que eso. Insistió en que le encantaba la psicología social, pero que se sentía frustrado por el desorden de los datos experimentales, que rara vez conducían a conclusiones claras. Su obsesión de toda la vida por la elegancia y el orden, según él, le llevó a inventar resultados sexys que las revistas encontraban atractivos, “Era una búsqueda de la estética, de la belleza, en lugar de la verdad”, dijo. Describió su comportamiento como una adicción que le llevaba a realizar actos de fraude cada vez más atrevidos, como un drogadicto que busca un estímulo mayor y mejor.
La comisión que investiga a Stapel concluyó que es culpable de varias prácticas, entre ellas:
- crear conjuntos de datos, que confirmaron en gran medida las expectativas previas,
- alterar los datos de los conjuntos de datos existentes,
- cambiar los instrumentos de medición sin informar del cambio, y
- tergiversar el número de sujetos experimentales.
Está claro que nunca es aceptable falsear los datos de la forma en que lo hizo este investigador. Sin embargo, a veces las violaciones de la ética no son tan fáciles de detectar.
Los investigadores tienen la responsabilidad de verificar que se siguen los métodos adecuados. El informe que describe la investigación del fraude de Stapel afirma que “los fallos estadísticos revelaron con frecuencia una falta de familiaridad con las estadísticas elementales”. Muchos de los coautores de Stapel deberían haber detectado irregularidades en sus datos. Desgraciadamente, no sabían mucho de análisis estadístico y se limitaban a confiar en que recopilaba y comunicaba los datos correctamente.
Muchos tipos de fraude estadístico son difíciles de detectar. Algunos investigadores simplemente dejan de recopilar datos una vez que tienen los suficientes para demostrar lo que esperaban comprobar. No quieren arriesgarse a que un estudio más extenso les complique la vida produciendo datos que contradigan su hipótesis.
Las organizaciones profesionales, como la American Statistical Association, definen claramente las expectativas de los investigadores. Incluso hay leyes en el código federal sobre el uso de datos de investigación.
Cuando un estudio estadístico utiliza participantes humanos, como en los estudios médicos, tanto la ética como la ley dictan que los investigadores deben tener en cuenta la seguridad de sus sujetos de investigación. El Departamento de Salud y Servicios Humanos de EE. UU. supervisa la normativa federal de los estudios de investigación con el objetivo de proteger a los participantes. Cuando una universidad u otra institución de investigación se dedica a la investigación, debe garantizar la seguridad de todos los sujetos humanos. Por esta razón, las instituciones de investigación establecen comités de supervisión conocidos como Juntas de Revisión Institucional (Institutional Review Boards, IRB). Todos los estudios previstos deben ser aprobados previamente por la IRB. Entre las principales protecciones que impone la ley se encuentran las siguientes:
- Los riesgos para los afiliados deben ser mínimos y razonables con respecto a los beneficios previstos.
- Los participantes deben dar su consentimiento informado, esto significa que los riesgos de la participación deben explicarse claramente a los sujetos del estudio, los sujetos deben dar su consentimiento por escrito y los investigadores están obligados a conservar la documentación de su consentimiento.
- Los datos recogidos de las personas deben ser custodiados cuidadosamente para proteger su privacidad.
Estas ideas pueden parecer fundamentales, pero pueden ser muy difíciles de verificar en la práctica. ¿Es suficiente eliminar el nombre de un participante del registro de datos para proteger la privacidad? Tal vez se pueda descubrir la identidad de la persona a partir de los datos que quedan. ¿Qué ocurre si el estudio no se desarrolla como estaba previsto y surgen riesgos que no se habían considerado? ¿Cuándo es realmente necesario el consentimiento informado? Supongamos que su médico quiere una muestra de sangre para comprobar su nivel de colesterol, una vez analizada la muestra, espera que el laboratorio se deshaga de la sangre restante, en ese momento la sangre se convierte en un residuo biológico. ¿Tiene un investigador derecho a tomarla para utilizarla en un estudio?
Es importante que los estudiantes de Estadística dediquen tiempo a considerar las cuestiones éticas que surgen en los estudios estadísticos. ¿Cuál es la prevalencia del fraude en los estudios estadísticos? Puede que se sorprenda y se decepcione. Existe un sitio web dedicado a catalogar las retractaciones de artículos de estudios que se han demostrado fraudulentos, un rápido vistazo mostrará que el mal uso de las estadísticas es un problema más grande de lo que la mayoría de la gente cree.
La vigilancia contra el fraude requiere conocimientos, el aprendizaje de la teoría básica de la estadística le capacitará para analizar críticamente los estudios estadísticos.
Fuente y licenciamiento
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0