Contenidos temáticos
- Medidas del centro de los datos
- Distorsión y media, mediana y moda
- Medidas de la dispersión de los datos
Desarrollo del tema
1. Medidas del centro de los datos
El “centro” de un conjunto de datos también es una forma de describir la ubicación. Las dos medidas más utilizadas del “centro” de los datos son la media (promedio) y la mediana. Para calcular el peso medio de 50 personas, sume los 50 pesos y los divide entre 50. Para calcular la mediana del peso de las 50 personas, ordene los datos y halle el número que divide los datos en dos partes iguales. La mediana suele ser una mejor medida del centro cuando hay valores extremos o atípicos porque no se ve afectada por los valores numéricos precisos de los atípicos, la media es la medida más común del centro.

NOTA. Las palabras “media” y “promedio” se suelen usar indistintamente. La sustitución de una palabra por otra es una práctica habitual. El término técnico es “media aritmética” y “promedio” es técnicamente un lugar central. Sin embargo, en la práctica, entre los no estadísticos, se suele aceptar “promedio” por “media aritmética”.
Cuando cada valor del conjunto de datos no es único, la media se puede calcular multiplicando cada valor distinto por su frecuencia y dividiendo después la suma por el número total de valores de los datos. La letra utilizada para representar la media muestral es una x con una barra encima (se pronuncia “barra de x”): x¯.
La letra griega μ (se pronuncia “mu”) representa la media de la población. Uno de los requisitos para que la media muestral sea una buena estimación de la media de la población es que la muestra tomada sea realmente aleatoria.
Para ver que ambas formas de calcular la media son iguales, considere la muestra: 1; 1; 1; 2; 2; 3; 4; 4; 4; 4; 4
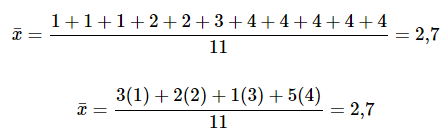
En el segundo cálculo, las frecuencias son 3, 2, 1 y 5.
Puede hallar rápidamente la ubicación de la mediana utilizando la expresión
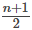
La letra n es el número total de valores de datos en la muestra. Si n es un número impar, la mediana es el valor del centro de los datos ordenados (ordenados de menor a mayor). Si n es un número par, la mediana es igual a los dos valores del centro sumados y divididos entre dos después de ordenar los datos. Por ejemplo, si el número total de valores de datos es de 97, entonces
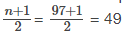
La mediana es el 49.º valor de los datos ordenados. Si el número total de valores de datos es 100, entonces
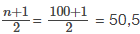
La mediana está a medio camino entre los valores 50.º y 51.º. La ubicación de la mediana y el valor de la mediana no son lo mismo. La letra M mayúscula se utiliza a menudo para representar la mediana. El siguiente ejemplo ilustra la ubicación de la mediana y su valor.
Ejemplo:
Los datos sobre el sida que indican el número de meses que vive un paciente con sida después de tomar un nuevo medicamento con anticuerpos son los siguientes (de menor a mayor):
3; 4; 8; 8; 10; 11; 12; 13; 14; 15; 15; 16; 16; 17; 17; 18; 21; 22; 22; 24; 24; 25; 26; 26; 27; 27; 29; 29; 31; 32; 33; 33; 34; 34; 35; 37; 40; 44; 44; 47;
Calcular la media y la mediana.
Solución:
El cálculo de la media es:
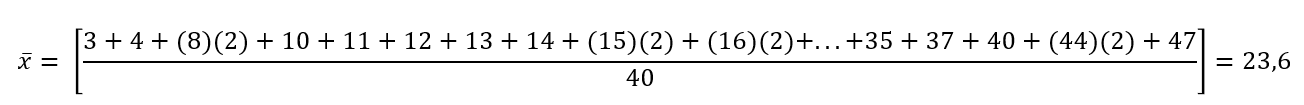
Para hallar la mediana, M, primero hay que utilizar la fórmula de la ubicación que es la siguiente:
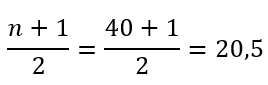
A partir del valor más pequeño, la mediana se sitúa entre los valores 20.º y 21.º (los dos 24): 3; 4; 8; 8; 10; 11; 12; 13; 14; 15; 15; 16; 16; 17; 17; 18; 21; 22; 22; 24; 24; 25; 26; 26; 27; 27; 29; 29; 31; 32; 33; 33; 34; 34; 35; 37; 40; 44; 44; 47;
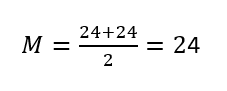
Otra medida del centro es la moda.
La moda es el valor más frecuente, puede haber más de una moda en un conjunto de datos siempre que esos valores tengan la misma frecuencia y esta sea la más alta, un conjunto de datos con dos modas se denomina bimodal.
Ejemplo:
Las calificaciones de los exámenes de Estadística de 20 estudiantes son las siguientes:
50; 53; 59; 59; 63; 63; 72; 72; 72; 72; 72; 76; 78; 81; 83; 84; 84; 84; 90; 93
Calcular la moda.
Solución:
La calificación más frecuente es 72, que aparece cinco veces. Moda = 72.
La ley de los grandes números y la media
La ley de los grandes números dice que, si se toman muestras de tamaño cada vez mayor de cualquier población, entonces la media x¯ de la muestra es muy probable que se acerque cada vez más a µ. Esto se analiza con más detalle más adelante en el texto.
Distribuciones muestrales y estadística de una distribución muestral
Se puede pensar en una distribución de muestreo como una distribución de frecuencia relativa con un gran número de muestras (vea la sección Muestreo y datos para hacer un repaso de la frecuencia relativa). Supongamos que se pregunta a treinta estudiantes seleccionados al azar el número de películas que vieron la semana anterior. Los resultados se encuentran en la tabla de frecuencias relativas que se muestra a continuación.
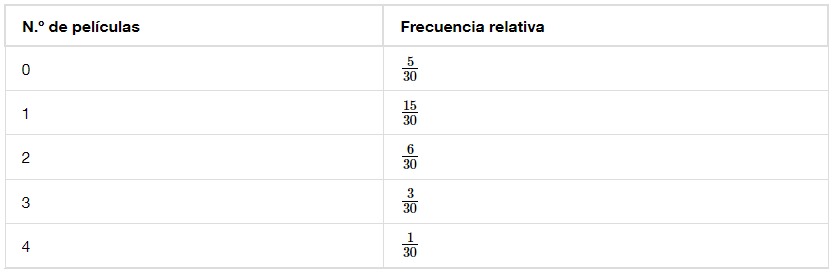
Si se deja que el número de muestras sea muy grande (por ejemplo, 300 millones o más), la tabla de frecuencias relativas se convierte en una distribución de frecuencias relativas.
Una estadística es un número calculado a partir de una muestra. Algunos ejemplos de estadísticas son la media, la mediana y la moda, entre otros. La media muestral x¯ es un ejemplo de estadística que estima la media poblacional μ.
Cálculo de la media de las tablas de frecuencias agrupadas
Cuando solo se dispone de datos agrupados no se conocen los valores individuales de los datos (solo conocemos los intervalos y las frecuencias de los intervalos); por lo tanto, no se puede calcular una media exacta para el conjunto de datos. Lo que debemos hacer es estimar la media real calculando la media de una tabla de frecuencias. Una tabla de frecuencias es una representación de datos en la que se muestran datos agrupados junto con las frecuencias correspondientes. Para calcular la media de una tabla de frecuencias agrupadas podemos aplicar la definición básica de media:
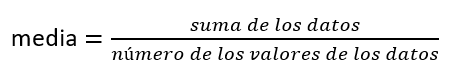
Simplemente tenemos que modificar la definición para que se ajuste a las restricciones de una tabla de frecuencias.
Como no conocemos los valores individuales de los datos podemos hallar el punto medio de cada intervalo. El punto medio es
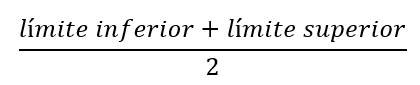
Ahora podemos modificar la definición de la media para que sea:
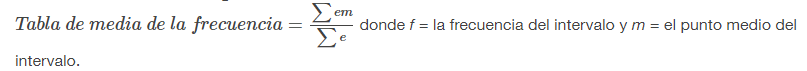
Ejemplo:
Se presenta una tabla de frecuencias que muestra la prueba estadística anterior del profesor Blount. Calcule la mejor estimación de la media de la clase.
| Intervalo de grado | Número de estudiantes |
|---|---|
| 50–56,5 | 1 |
| 56,5–62,5 | 0 |
| 62,5–68,5 | 4 |
| 68,5–74,5 | 4 |
| 74,5–80,5 | 2 |
| 80,5–86,5 | 3 |
| 86,5–92,5 | 4 |
| 92,5–98,5 | 1 |
Solución:
Calcula los puntos medios de todos los intervalos
| Intervalo de grado | Número de estudiantes |
|---|---|
| 50–56,5 | 53,25 |
| 56,5–62,5 | 59,5 |
| 62,5–68,5 | 65,5 |
| 68,5–74,5 | 71,5 |
| 74,5–80,5 | 77,5 |
| 80,5–86,5 | 83,5 |
| 86,5–92,5 | 89,5 |
| 92,5–98,5 | 95,5 |
- Calcule la suma del producto de la frecuencia de cada intervalo y el punto medio.
∑em∑em53,25(1)+59,5(0)+65,5(4)+71,5(4)+77,5(2)+83,5(3)+89,5(4)+95,5(1)=1460,25
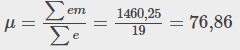
2. Distorsión y media, mediana y moda
Considere el siguiente conjunto de datos. 4; 5; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 10
Este conjunto de datos se puede representar mediante el siguiente histograma. Cada intervalo tiene un ancho de uno y cada valor se sitúa en el centro de un intervalo.
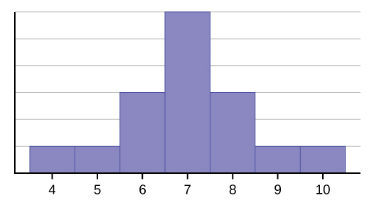
El histograma muestra una distribución simétrica de los datos. Una distribución es simétrica si se puede trazar una línea vertical en algún punto del histograma de manera que la forma a la izquierda y a la derecha de la línea vertical sean imágenes una espejo de la otra. La media, la mediana y la moda son siete para estos datos. En una distribución perfectamente simétrica, la media y la mediana son iguales. Este ejemplo tiene una moda (unimodal), y la moda es la misma que la media y la mediana. En una distribución simétrica que tiene dos modas (bimodal), las dos modas serían diferentes de la media y la mediana.
El histograma de los datos: 4; 5; 6; 6; 6; 7; 7; 7; 7; 8 (que se muestra en la siguiente figura) no es simétrico. El lado derecho parece “cortado” en comparación con el lado izquierdo. Una distribución de este tipo se denomina distorsionada a la izquierda porque se desplaza hacia la izquierda.
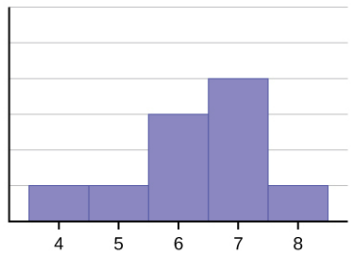
La media es 6,3, la mediana es 6,5 y la moda es siete. Observa que la media es menor que la mediana y ambas son menores que la moda. Tanto la media como la mediana reflejan la distorsión, pero la media lo refleja más.
El histograma de los datos: 6; 7; 7; 7; 7; 8; 8; 8; 9; 10 de la siguiente figura tampoco es simétrico. Es distorsionada a la derecha.
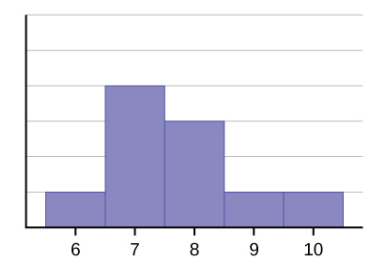
La media es 7,7, la mediana es 7,5 y la moda es siete. De las tres estadísticas, la media es la mayor, mientras que la moda es la menor. De nuevo, la media es la que más refleja la distorsión.
Para resumir, generalmente si la distribución de los datos está distorsionada a la izquierda, la media es menor que la mediana, que suele ser menor que la moda. Si la distribución de los datos está distorsionada a la derecha, la moda suele ser menor que la mediana, que es menor que la media.
La distorsión y la simetría son importantes cuando hablemos de distribuciones de probabilidad en capítulos posteriores.
3. Medidas de la dispersión de los datos
Una característica importante de cualquier conjunto de datos es su variación. En algunos conjuntos de datos, los valores de los datos se concentran muy cerca de la media; en otros, están más dispersos de la media. La medida más común de variación, o dispersión, es la desviación típica. La desviación típica es un número que mide la distancia entre los valores de los datos y su media.
La desviación típica
- proporciona una medida numérica de la cantidad global de variación en un conjunto de datos y
- se puede usar para determinar si un valor de datos determinado está cerca o lejos de la media.
La desviación típica proporciona una medida de la variación global de un conjunto de datos
La desviación típica es siempre positiva o cero. La desviación típica es pequeña cuando todos los datos se concentran cerca de la media y muestran poca variación o dispersión. La desviación típica es mayor cuando los valores de los datos están más alejados de la media y muestran más variación.
Supongamos que estudiamos el tiempo que los clientes esperan en la fila de la caja del supermercado A y del supermercado B. El tiempo promedio de espera en ambos supermercados es de cinco minutos. En el supermercado A, la desviación típica del tiempo de espera es de dos minutos; en el supermercado B, la desviación típica del tiempo de espera es de cuatro minutos.
Como el supermercado B tiene una desviación típica más alta, sabemos que hay más variación en los tiempos de espera en el supermercado B. En general, los tiempos de espera en el supermercado B están más dispersos del promedio; los tiempos de espera en el supermercado A están más concentrados cerca del promedio.
La desviación típica se puede usar para determinar si un valor de los datos está cerca o lejos de la media.
Supongamos que Rosa y Binh compran en el supermercado A. Rosa espera en la caja siete minutos y Binh espera un minuto. En el supermercado A, el tiempo medio de espera es de cinco minutos y la desviación típica es de dos minutos. La desviación típica se puede usar para determinar si un valor de los datos está cerca o lejos de la media.
Rosa espera siete minutos:
- Siete son dos minutos más que el promedio de cinco; dos minutos equivalen a una desviación típica.
- El tiempo de espera de Rosa, de siete minutos, es dos minutos más largo que el promedio de cinco minutos.
- El tiempo de espera de Rosa, de siete minutos, está una desviación típica por encima del promedio de cinco minutos.
Binh espera un minuto.
- Uno es cuatro minutos menos que el promedio de cinco; cuatro minutos equivalen a dos desviaciones típicas.
- El tiempo de espera de Binh, de un minuto, es cuatro minutos menos que el promedio de cinco minutos.
- El tiempo de espera de Binh, de un minuto, está dos desviaciones típicas por debajo del promedio de cinco minutos.
- Un valor de los datos que está a dos desviaciones típicas del promedio está justo en el límite de lo que muchos estadísticos considerarían alejado del promedio. Plantearse que los datos están lejos de la media si están a más de dos desviaciones típicas es más una “regla general” aproximada que una regla rígida. En general, la forma de la distribución de los datos afecta a la cantidad de datos que se encuentran más allá de dos desviaciones típicas. (En los capítulos siguientes aprenderá más sobre este punto).
La recta numérica puede ayudarlo a entender la desviación típica. Si ponemos el cinco y el siete en una recta numérica, el siete está a la derecha del cinco. Decimos, entonces, que siete está una desviación típica a la derecha de cinco porque 5 + (1)(2) = 7.
Si el número uno también formara parte del conjunto de datos, entonces estaría dos desviaciones típicas a la izquierda de cinco porque 5 + (-2)(2) = 1.

- En general, un valor = media + (n.º de STDEV) (número de STandard DEViation, o desviación típica)
- donde n.º de STDEV = el número de desviaciones típicas
- El n.º de STDEV no tiene que ser un número entero
- Uno es dos desviaciones típicas menos que la media de cinco porque: 1 = 5 + (-2)(2).
La ecuación valor = media + (n.º de STDEV)(desviación típica) puede expresarse para una muestra y para una población.
La letra minúscula s representa la desviación típica de la muestra y la letra griega σ (sigma, minúscula) representa la desviación típica de la población. El símbolo
es la media muestral y el símbolo griego μ es la media de la población.
Cálculo de la desviación típica
Si x es un número, la diferencia “x – media” se llama su desviación. En un conjunto de datos hay tantas desviaciones como elementos en el conjunto de datos. Las desviaciones se utilizan para calcular la desviación típica. Si los números pertenecen a una población, en símbolos una desviación es x – μ. Para los datos de la muestra, en símbolos una desviación es:
El procedimiento para calcular la desviación típica depende de si los números son toda la población o son datos de una muestra. Los cálculos son similares, pero no idénticos. Por tanto, el símbolo utilizado para representar la desviación típica depende de si se calcula a partir de una población o de una muestra. La letra minúscula s representa la desviación típica de la muestra y la letra griega σ (sigma, minúscula) representa la desviación típica de la población. Si la muestra tiene las mismas características que la población, entonces s debería ser una buena estimación de σ.
Para calcular la desviación típica, tenemos que calcular primero la varianza. La varianza es el promedio de los cuadrados de las desviaciones (la x – x¯ para una muestra, o los valores x – μ para una población). El símbolo σ2 representa la varianza de la población; la desviación típica de la población σ es la raíz cuadrada de la varianza de la población. El símbolo s2 representa la varianza de la muestra; la desviación típica de la muestra s es la raíz cuadrada de la varianza de la muestra. Puede pensar en la desviación típica como un promedio especial de las desviaciones.
Si las cifras proceden de un censo de toda la población y no de una muestra, cuando calculamos el promedio de las desviaciones al cuadrado para hallar la varianza, dividimos entre N, el número de elementos de la población. Si los datos proceden de una muestra y no de una población, al calcular el promedio de las desviaciones al cuadrado, dividimos entre n – 1, uno menos que el número de elementos de la muestra.
Fórmulas para la desviación típica de la muestra
Para la desviación típica de la muestra, el denominador es n – 1, es decir, el tamaño de la muestra MENOS 1.
Fórmulas para la desviación típica de la población
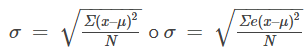
Para la desviación típica de la población el denominador es N, el número de elementos de la población.
En estas fórmulas, f representa la frecuencia con la que aparece un valor. Por ejemplo, si un valor aparece una vez, f es uno. Si un valor aparece tres veces en el conjunto de datos o población, f es tres.
Variabilidad muestral de una estadística
La estadística de una distribución muestral se trató en Estadística descriptiva: medidas del centro de los datos. El grado de variación de la estadística de una muestra a otra se conoce como variabilidad muestral de una estadística. Normalmente se mide la variabilidad muestral de una estadística por su error estándar. El error estándar de la media es un ejemplo de error estándar. Es una desviación típica especial y se conoce como la desviación típica de la distribución muestral de la media. La notación para el error estándar de la media es
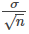
donde σ es la desviación típica de la población y n es el tamaño de la muestra.
NOTA. En la práctica, UTILICE UNA CALCULADORA O UN SOFTWARE DE COMPUTADORA PARA CALCULAR LA DESVIACIÓN TÍPICA. Si está utilizando una calculadora TI-83, 83+ u 84+, debe seleccionar la desviación típica σx o sx correspondiente de las estadísticas de resumen. Nos centraremos en la utilización e interpretación de la información que nos proporciona la desviación típica. Sin embargo, debería estudiar el siguiente ejemplo paso a paso para entender cómo la desviación típica mide la variación de la media. (Las instrucciones de la calculadora aparecen al final de este ejemplo).
Ejemplo:
En una clase de quinto grado la maestra estaba interesada en la edad promedio y la desviación típica de la muestra de las edades de sus estudiantes. Los siguientes datos son las edades de una MUESTRA de n = 20 estudiantes de quinto grado. Las edades están redondeadas al medio año más cercano:
9; 9,5; 9,5; 10; 10; 10; 10; 10,5; 10,5; 10,5; 10,5; 11; 11; 11; 11; 11; 11; 11,5; 11,5; 11,5;
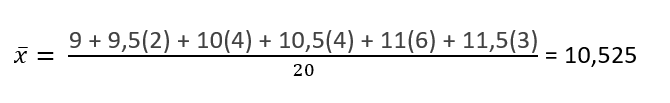
La edad promedio es de 10,53 años, redondeada a dos cifras.
La varianza se puede calcular mediante una tabla. A continuación se calcula la desviación típica tomando la raíz cuadrada de la varianza. Explicaremos las partes de la tabla después de calcular s.
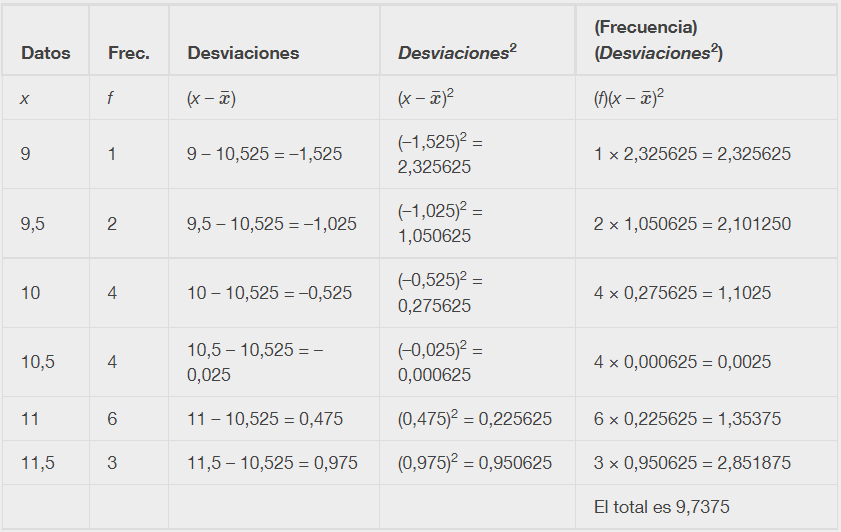
La varianza de la muestra, s2, es igual a la suma de la última columna (9,7375) dividida entre el número total de valores de datos menos uno (20 – 1):
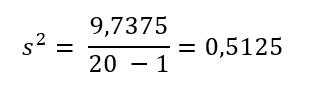
La desviación típica de la muestra s es igual a la raíz cuadrada de la varianza de la muestra:
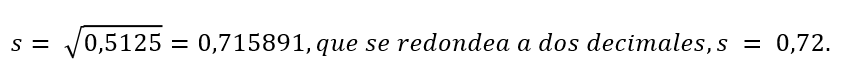
Normalmente, el cálculo de la desviación típica se realiza en la calculadora o en la computadora. Los resultados intermedios no están redondeados para mayor exactitud.
- En los siguientes problemas, recuerda que valor = media + (n.º de STDEV)(desviación típica). Compruebe la media y la desviación típica con una calculadora o una computadora.
- Para una muestra:
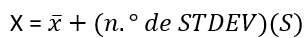
- Para una población:
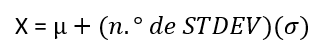
- Para este ejemplo, utilice
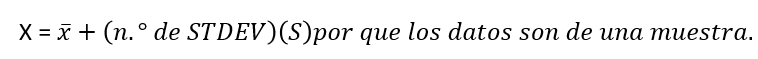
a. Compruebe la media y la desviación típica en su calculadora o computadora.
b. Halla el valor que está una desviación típica por encima de la media. Calcule (x¯ + 1s).
c. Halla el valor que está dos desviaciones típicas por debajo de la media. Calcule (x¯ – 2s).
d. Halle los valores que están a 1,5 desviaciones típicas de (por debajo y por encima) la media.
Solución:
a. USO DE LAS CALCULADORAS TI-83, 83+, 84, 84+
- Borre las listas L1 y L2. Pulse STAT 4:ClrList. Introduzca el 2nd 1 para L1, la coma (,), y el 2nd 2 para L2.
- Introduzca los datos en el editor de listas. Pulse STAT 1:EDIT. Si es necesario, borre las listas subiendo con la flecha hasta el nombre. Pulse CLEAR y mueva la flecha hacia abajo.
- Ponga los valores de los datos (9, 9,5, 10, 10,5, 11, 11,5) en la lista L1 y las frecuencias (1, 2, 4, 4, 6, 3) en la lista L2. Utilice las teclas de flecha para moverse.
- Pulse STAT y la flecha hacia CALC. Pulse 1:1-VarStats e introduzca L1 (2nd 1), L2 (2nd 2). No olvide la coma. Pulse ENTER.
- x¯ = 10,525
- Utilice Sx porque se trata de datos de muestra (no de una población): Sx=0,715891
b. (x¯ + 1s) = 10,53 + (1)(0,72) = 11,25
c. (x¯ – 2s) = 10,53 – (2)(0,72) = 9,09
d. (x¯ – 1,5s) = 10,53 – (1,5)(0,72) = 9,45
(x¯ + 1,5s) = 10,53 + (1,5)(0,72) = 11,61
Explicación del cálculo de la desviación típica que aparece en la tabla
Las desviaciones muestran la dispersión de los datos respecto a la media. El valor de los datos 11,5 está más alejado de la media que el valor de los datos 11, lo que se indica con las desviaciones 0,97 y 0,47. Una desviación positiva se produce cuando el valor de los datos es mayor que la media, mientras que una desviación negativa se produce cuando el valor de los datos es menor que la media. La desviación es de –1,525 para el noveno valor de los datos. Si se suman las desviaciones, la suma es siempre cero (según el Ejemplo 2.32, hay n = 20 desviaciones). Por lo tanto, no se puede simplemente sumar las desviaciones para obtener la dispersión de los datos. Al elevar al cuadrado las desviaciones se convierten en números positivos, y la suma también será positiva. La varianza, por tanto, es la desviación promedio al cuadrado.
La varianza es una medida al cuadrado y no tiene las mismas unidades que los datos. Calcular la raíz cuadrada resuelve el problema. La desviación típica mide la dispersión en las mismas unidades que los datos.
Observa que en vez de dividir entre n = 20, el cálculo divide entre n – 1 = 20 – 1 = 19 porque los datos son una muestra. Para la varianza de la muestra, se divide entre el tamaño de la muestra menos uno (n – 1). ¿Por qué no dividir entre n? La respuesta tiene que ver con la varianza de la población. La varianza de la muestra es una estimación de la varianza de la población. Basándose en la matemática teórica que hay detrás de estos cálculos, al dividir entre (n – 1) da una mejor estimación de la varianza de la población.
NOTA. Debes concentrarte en lo que la desviación típica nos dice sobre los datos. La desviación típica es un número que mide la dispersión de los datos con respecto a la media. Efectúe la aritmética con una calculadora o una computadora.
La desviación típica, s o σ, es cero o mayor que cero. La descripción de los datos con referencia a la dispersión se denomina “variabilidad”. La variabilidad de los datos depende del método con el que se obtienen los resultados; por ejemplo, por medición o por muestreo aleatorio. Cuando la desviación típica es cero, no hay dispersión; es decir, todos los valores de los datos son iguales entre sí. La desviación típica es pequeña cuando todos los datos se concentran cerca de la media, y es mayor cuando los valores de los datos muestran más variación con respecto a la media. Cuando la desviación típica es mucho mayor que cero, los valores de los datos están muy dispersos alrededor de la media; los valores atípicos pueden hacer que s o σ sean muy grandes.
La desviación típica, cuando se presenta por primera vez, puede parecer poco clara. Al graficar los datos, puede tener una mejor “percepción” de las desviaciones y la desviación típica. Encontrará que en las distribuciones simétricas la desviación típica puede ser muy útil, pero en las distribuciones sesgadas, es posible que la desviación típica no sea de mucha ayuda. La razón es que los dos lados de una distribución sesgada tienen diferentes márgenes. En una distribución sesgada, es mejor fijarse en el primer cuartil, la mediana, el tercer cuartil, el valor más pequeño y el valor más grande. Como los números pueden ser confusos, siempre hay que hacer un gráfico de los datos. Visualice sus datos en un histograma o un diagrama de caja y bigotes.
Ejemplo:
Utiliza los siguientes datos (calificaciones del primer examen) de la clase de Precálculo de primavera de Susan Dean:
33; 42; 49; 49; 53; 55; 55; 61; 63; 67; 68; 68; 69; 69; 72; 73; 74; 78; 80; 83; 88; 88; 88; 90; 92; 94; 94; 94; 94; 96; 100
a. Crea un gráfico que contenga los datos, las frecuencias, las frecuencias relativas y las frecuencias relativas acumuladas con tres decimales.
b. Calcula lo siguiente con un decimal utilizando una calculadora TI-83+ o TI-84:
i. La media muestral
ii. La desviación típica de la muestra
iii. La mediana
iv. El primer cuartil
v. El tercer cuartil
vi. IQR
c. Construye un diagrama de caja y bigotes y un histograma en el mismo conjunto de ejes. Comenta sobre el diagrama de caja y bigotes, el histograma y el gráfico.
Solución:
El largo bigote izquierdo del diagrama de caja y bigotes se refleja en la parte izquierda del histograma. La dispersión de las calificaciones del examen en el 50 % inferior es mayor (73 – 33 = 40) que la dispersión en el 50 % superior (100 – 73 = 27). El histograma, el diagrama de caja y bigotes y el gráfico lo reflejan. Hay un número considerable de notas A y B (80, 90 y 100). El histograma lo muestra claramente. El diagrama de caja y bigotes nos muestra que el 50 % de las calificaciones del examen (IQR = 29) son D, C y B. El diagrama de caja también nos muestra que el 25 % inferior de las puntuaciones del examen son D y F.
Desviación típica de las tablas de frecuencia agrupadas
Recordemos que para los datos agrupados no conocemos los valores individuales de los datos, por lo que no podemos describir el valor típico de los datos con precisión. En otras palabras, no podemos hallar la media, la mediana ni la moda exactas. Sin embargo, podemos determinar la mejor estimación de las medidas de centro al hallar la media de los datos agrupados con la fórmula
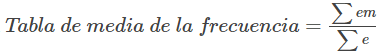
donde e= frecuencias de intervalo y m = puntos medios del intervalo.
Al igual que no podemos hallar la media exacta, tampoco podemos hallar la desviación típica exacta. Recuerde que la desviación típica describe numéricamente la desviación esperada que tiene un valor de datos con respecto a la media. En términos sencillos, la desviación típica nos permite comparar lo “inusual” que son los datos individuales en comparación con la media.
Ejemplo:
Calcular la desviación típica de los datos:
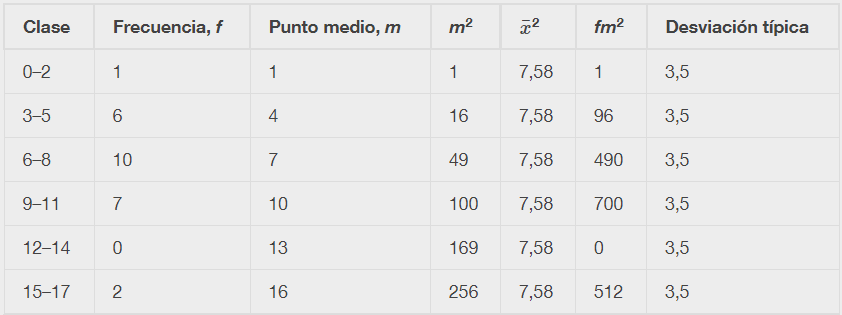
Para este conjunto de datos, tenemos la media, x¯ = 7,58 y la desviación típica, sx = 3,5. Esto significa que se espera que un valor de datos seleccionado al azar se aleje 3,5 unidades de la media. Si observamos la primera clase, vemos que el punto medio de la clase es igual a uno. Esto supone casi dos desviaciones típicas completas de la media, ya que 7,58 – 3,5 – 3,5 = 0,58. La fórmula para calcular la desviación típica no es complicada,
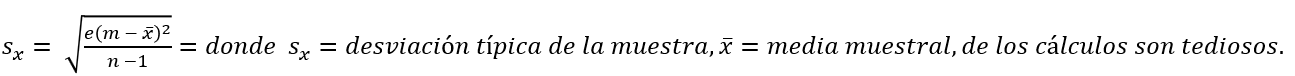
Por lo general, lo mejor es utilizar la tecnología para realizar los cálculos.
Comparación de valores de diferentes conjuntos de datos
La desviación típica es útil cuando se comparan valores de datos que provienen de diferentes conjuntos de datos. Si los conjuntos de datos tienen medias y desviaciones típicas diferentes, la comparación directa de los valores de los datos puede ser engañosa.
- Calcula cuántas desviaciones típicas se alejan de su media para cada valor de los datos.
- Utiliza la fórmula: valor = media + (n.º de STDEV)(desviación típica); resuelva para n.º de STDEVs.
- n.ºoeSTDEVs=valor – mediadesviación típica

N.º de STDEV suele llamarse “puntuación z”; podemos utilizar el símbolo z. En símbolos, las fórmulas se convierten en:

Las siguientes listas ofrecen algunos hechos que proporcionan un poco más de información sobre lo que la desviación típica nos dice sobre la distribución de los datos.
Para CUALQUIER conjunto de datos, no importa cuál sea la distribución de los datos:
- Al menos el 75 % de los datos están dentro de las dos desviaciones típicas de la media.
- Al menos el 89 % de los datos están dentro de las tres desviaciones típicas de la media.
- Al menos el 95 % de los datos están dentro de 4,5 desviaciones típicas de la media.
- Esto se conoce como la regla de Chebyshev.
Para los datos que tienen una distribución en FORMA DE CAMPANA y SIMÉTRICA:
- Aproximadamente el 68 % de los datos están dentro de una desviación típica de la media.
- Aproximadamente el 95 % de los datos están dentro de las dos desviaciones típicas de la media.
- Más del 99 % de los datos están dentro de las tres desviaciones típicas de la media.
- Esto se conoce como la regla empírica.
- Es importante señalar que esta regla solo se aplica cuando la forma de la distribución de los datos tiene forma de campana y es simétrica. Aprenderemos más sobre esto cuando estudiemos la distribución de probabilidad “normal” o “gaussiana” en capítulos posteriores.
Fuente y licenciamiento
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0