Objetivos didácticos
Al final de este capítulo el estudiante podrá:
- Reconocer y comprender las funciones de distribución de probabilidad discreta, en general.
- Calcular e interpretar los valores esperados.
- Reconocer la distribución de probabilidad binomial y aplicarla adecuadamente.
- Reconocer la distribución de probabilidad de Poisson y aplicarla adecuadamente.
Introducción
Un estudiante responde un cuestionario de diez preguntas de verdadero-falso. Como el estudiante tenía una agenda tan apretada, no podía estudiar y estimaba al azar cada respuesta. ¿Cuál es la probabilidad de que el estudiante apruebe el examen con, al menos, el 70 %?
Hay pequeñas compañías que pueden estar interesadas en el número de llamadas telefónicas de larga distancia que hacen sus empleados en las horas pico del día. Supongamos que el promedio es de 20 llamadas. ¿Cuál es la probabilidad de que los empleados hagan más de 20 llamadas de larga distancia durante las horas pico?
Estos dos ejemplos ilustran dos tipos diferentes de problemas de probabilidad que implican variables aleatorias discretas. Recordemos que los datos discretos son datos que se pueden contar. Una variable aleatoria describe con palabras los resultados de un experimento estadístico. Los valores de una variable aleatoria pueden variar con cada repetición de un experimento.
Notación de la variable aleatoria
Las letras mayúsculas como X o Y denotan una variable aleatoria. Las letras minúsculas como x o y denotan el valor de una variable aleatoria. Si X es una variable aleatoria, entonces X se escribe con palabras y x se da como un número.
Por ejemplo, supongamos que X = el número de caras que se obtiene al lanzar tres monedas imparciales. El espacio muestral para el lanzamiento de tres monedas imparciales es TTT; THH; HTH; HHT; HTT; THT; TTH; HHH. Entonces, x = 0, 1, 2, 3. X está en palabras y x es un número. Observe que para este ejemplo los valores de x son resultados contables. Como se pueden contar los posibles valores que puede tomar X y los resultados son aleatorios (los valores de x 0, 1, 2, 3), X es una variable aleatoria discreta.

Desarrollo del tema
1. Función de Distribución de Probabilidad (PDF) para una variable aleatoria discreta
Una función de distribución de probabilidad discreta tiene dos características:
- Cada probabilidad está entre cero y uno, ambos inclusive.
- La suma de las probabilidades es uno.
Ejemplo:
Un psicólogo infantil se interesa por el número de veces que el llanto de un recién nacido despierta a su madre después de la medianoche. Para una muestra aleatoria de 50 madres, se obtuvo la siguiente información. Supongamos que X = el número de veces por semana que el llanto de un recién nacido despierta a su madre después de la medianoche. En este ejemplo, x = 0, 1, 2, 3, 4, 5.
P(x) = probabilidad de que X tome un valor x.
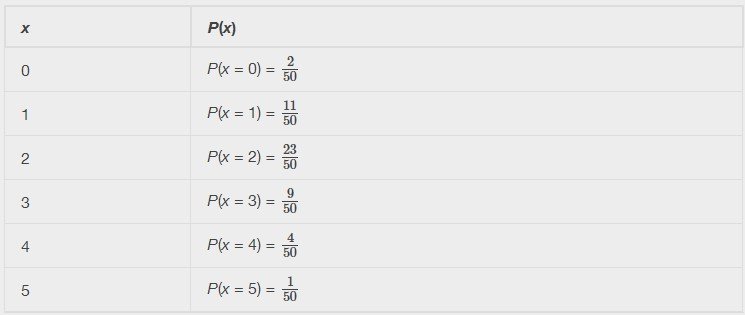
X toma los valores 0, 1, 2, 3, 4, 5. Esta es una PDF discreta porque:
a. Cada P(x) está entre cero y uno, ambos inclusive.
b. La suma de las probabilidades es uno, es decir,
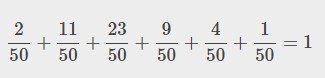
2. Media o valor esperado y desviación típica
El valor esperado suele denominarse media o promedio “a largo plazo”. Esto significa que a largo plazo de hacer un experimento una y otra vez, se esperaría este promedio.
Se lanza una moneda y se anota el resultado. ¿Cuál es la probabilidad de que el resultado sea cara? Si lanza una moneda dos veces, ¿la probabilidad le dice que estos lanzamientos darán como resultado una cara y una cruz? Puede lanzar una moneda diez veces y registrar nueve caras. Ofrece información sobre lo que cabe esperar a largo plazo. ¡Para demostrarlo, Karl Pearson lanzó una vez una moneda justa 24.000 veces! Registró los resultados de cada lanzamiento, obteniendo cara 12.012 veces. En su experimento, Pearson ilustró la ley de los grandes números.
La ley de los grandes números establece que, a medida que aumenta el número de ensayos en un experimento de probabilidad, la diferencia entre la probabilidad teórica de un evento y la frecuencia relativa se aproxima a cero (la probabilidad teórica y la frecuencia relativa se acercan cada vez más). Al evaluar los resultados a largo plazo de los experimentos estadísticos, a menudo queremos conocer el resultado del “promedio”. Este “promedio a largo plazo” se conoce como la media o valor esperado del experimento y se denota con la letra griega μ. En otras palabras, después de realizar muchos ensayos de un experimento, se esperaría este valor promedio.
NOTA. Para hallar el valor esperado o promedio a largo plazo, μ, basta con multiplicar cada valor de la variable aleatoria por su probabilidad y sumar los productos.
Ejemplo:
Un equipo de fútbol masculino juega al fútbol en cero, en uno o en dos días a la semana. La probabilidad de que jueguen cero días es de 0,2, la de que jueguen un día es de 0,5 y la de que jueguen dos días es de 0,3. Calcule el promedio a largo plazo o el valor esperado, μ, del número de días por semana que el equipo de fútbol masculino juega al fútbol.
Para resolver el problema, primero dejemos la variable aleatoria X = el número de días que el equipo de fútbol masculino juega al fútbol por semana. X toma los valores 0, 1, 2 Construya una tabla PDF añadiendo una columna x*P(x). En esta columna, multiplicará cada valor de x por su probabilidad.
| x | P(x) | x*P(x) |
|---|---|---|
| 0 | 0,2 | (0)(0,2) = 0 |
| 1 | 0,5 | (1)(0,5) = 0,5 |
| 2 | 0,3 | (2)(0,3) = 0,6 |
Añada la última columna x*P(x) para hallar las intersecciones en el promedio a largo plazo o el valor esperado: (0)(0,2) + (1)(0,5) + (2)(0,3) = 0 + 0,5 + 0,6 = 1,1.
El valor esperado es 1,1. El equipo de fútbol masculino tendría, en promedio, que jugar al fútbol 1,1 días por semana. El número 1,1 es el promedio a largo plazo o el valor esperado si el equipo de fútbol masculino juega al fútbol semana tras semana. Decimos que μ = 1,1.
Al igual que los datos, las distribuciones de probabilidad tienen desviaciones típicas. Para calcular la desviación típica(σ) de una distribución de probabilidad, halle cada desviación de su valor esperado, elévela al cuadrado, multiplíquela por su probabilidad, sume los productos y calcule la raíz cuadrada. Para entender cómo hacer el cálculo, observe la tabla del número de días por semana que un equipo de fútbol masculino juega al fútbol. Para calcular la desviación típica, sume las entradas de la columna marcada como (x – μ)2P(x) y calcule la raíz cuadrada.

Sume la última columna de la tabla. 0,242 + 0,005 + 0,243 = 0,490. La desviación típica es la raíz cuadrada de 0,49, es decir,
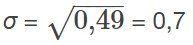
Generalmente, para las distribuciones de probabilidad, utilizamos una calculadora o una computadora para calcular μ y σ para reducir el error de redondeo. Para algunas distribuciones de probabilidad, existen fórmulas abreviadas para calcular μ y σ.
Ejemplo:
El 11 de mayo de 2013 a las 09:30 p. m., la probabilidad de que se produjera una actividad sísmica moderada (un terremoto moderado) en las próximas 48 horas en Irán era de aproximadamente el 21,42 %. Suponga que hace una apuesta a que se producirá un terremoto moderado en Irán durante este periodo. Si gana la apuesta, gana 50 dólares. Si pierde la apuesta, paga 20 dólares. Supongamos que X = el monto de ganancia de una apuesta.
P(ganar) = P(se producirá un terremoto moderado) = 21,42 %
P(pérdida) = P( no se producirá un terremoto moderado) = 100 % – 21,42 %
Si apuesta muchas veces, ¿saldrá ganando? Explique su respuesta en una frase completa utilizando números. ¿Cuál es la desviación típica de X?
Solución:

Media = Valor esperado = 10,71 + (-15,716) = -5,006.
Si hace esta apuesta muchas veces en las mismas condiciones, su resultado a largo plazo será una pérdida promedio de 5,01 dólares por apuesta.
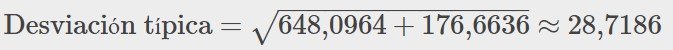
Algunas de las funciones de probabilidad discreta más comunes son la binomial, la geométrica, la hipergeométrica y la de Poisson. La mayoría de los cursos elementales no cubren la geométrica, la hipergeométrica y la Poisson. Su instructor le hará saber si desea cubrir estas distribuciones.
Una función de distribución de probabilidad es un patrón. Intente adaptar un problema de probabilidad en un patrón o distribución para realizar los cálculos necesarios. Estas distribuciones son herramientas que facilitan la resolución de problemas de probabilidad. Cada distribución tiene sus propias características especiales. Aprender las características le permite distinguir entre las diferentes distribuciones.
3. Distribución binomial
El experimento binomial tiene tres características.
- Hay un número fijo de ensayos. Piense en los ensayos como repeticiones de un experimento. La letra n indica el número de ensayos.
- Solo hay dos resultados posibles, llamados “acierto” y “fallo” para cada ensayo. La letra p denota la probabilidad de acierto en un ensayo, y la q la probabilidad de fracaso en un ensayo. p + q = 1.
- Los n ensayos son independientes y se repiten utilizando condiciones idénticas. Como los n ensayos son independientes, el resultado de un ensayo no ayuda a predecir el resultado de otro. Otra forma de decir esto es que para cada ensayo individual la probabilidad, p, de un acierto y la probabilidad, q, de un fallo siguen siendo las mismas. Por ejemplo, estimar al azar una pregunta de estadística de verdadero-falso solo tiene dos resultados. Si un acierto es estimar correctamente, un fallo es estimar incorrectamente. Supongamos que Joe siempre acierta en cualquier pregunta de Estadística de verdadero-falso con una probabilidad p = 0,6. Entonces, q = 0,4. Esto significa que para cada pregunta de estadística de verdadero-falso que responda Joe su probabilidad de acierto (p = 0,6) y su probabilidad de fallo (q = 0,4) siguen siendo las mismas.
Los resultados de un experimento binomial se ajustan a una distribución de probabilidad binomial. La variable aleatoria X = el número de aciertos obtenidos en los n ensayos independientes.

Cualquier experimento que tenga las características dos y tres y en el que n = 1 se llama Ensayo de Bernoulli (llamado así por Jacob Bernoulli que, a finales de 1600, los estudió ampliamente). Un experimento binomial se produce cuando se cuenta el número de aciertos en uno o más ensayos de Bernoulli.
Ejemplo:
Aproximadamente el 70 % de los estudiantes de Estadística hacen sus tareas para la casa a tiempo para que sean recopiladas y calificadas. Cada estudiante lo hace de forma independiente. En una clase de Estadística de 50 estudiantes, ¿cuál es la probabilidad de que, al menos, 40 hagan la tarea para la casa a tiempo? Los estudiantes son seleccionados al azar.
a. Se trata de un problema binomial porque solo hay un acierto o un __, hay un número fijo de ensayos y la probabilidad de acierto es de 0,70 para cada ensayo.
b. Si nos interesa el número de estudiantes que hacen la tarea para la casa a tiempo, ¿cómo definimos X?
c. ¿Qué valores toma x?
d. ¿Qué es un “fallo” en palabras?
e. Si p + q = 1, ¿qué es q?
f. ¿Como qué tipo de inecuación se traducen las palabras “al menos” para la pregunta de probabilidad P(x __ 40)?
Solución:
a. fallo
b. X = número de estudiantes de Estadística que hacen la tarea para la casa a tiempo
c. 0, 1, 2, …, 50
d. Fallo se define como un estudiante que no termina sus tareas para la casa a tiempo.
La probabilidad de acierto es p = 0,70. El número de ensayos es n = 50
e. q = 0,30
f. mayor o igual que (≥)
La pregunta de probabilidad es P(x ≥ 40).
4. Distribución geométrica
Hay tres características principales de un experimento geométrico.
- Hay uno o más ensayos de Bernoulli con todos los fallos excepto el último, que es un acierto. En otras palabras, sigue repitiendo lo que está haciendo hasta el primer acierto. Entonces se detiene. Por ejemplo, se lanza un dardo a una diana hasta dar en ella. La primera vez que logra dar en la diana es un “acierto”, así que deja de lanzar el dardo. Puede que le lleve seis intentos hasta que acierte en la diana. Puede pensar en las pruebas como fallo, fallo, fallo, fallo, acierto, PARAR.
- En teoría, el número de pruebas podría ser eterno. Debe haber, al menos, un ensayo.
- La probabilidad, p, de un acierto y la probabilidad, q, de un fallo es igual para cada ensayo. p + q = 1 y q = 1 – p. Por ejemplo, la probabilidad de sacar un tres al lanzar un dado imparcial es 1616. Esto es cierto sin importar cuántas veces se lance el dado. Supongamos que quiere saber la probabilidad de obtener el primer tres en la quinta lanzada. En las lanzadas del uno al cuatro, no se obtiene un lado con un tres. La probabilidad de cada una de las lanzadas es
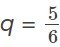
la probabilidad de un fallo. La probabilidad de obtener un tres en la quinta lanzada es:
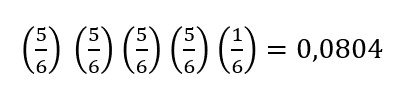
X = el número de ensayos independientes hasta el primer acierto.
Ejemplo:
Supongamos que busca a un estudiante de su instituto universitario que vive a menos de ocho millas de usted. Sabe que el 55 % de los 25.000 estudiantes viven a menos de ocho millas de usted. Contacta al azar con estudiantes del instituto universitario hasta que uno diga que vive a menos de ocho millas de usted. ¿Cuál es la probabilidad de que tenga que contactar cuatro personas?
Este es un problema geométrico porque puede tener varios fallos antes de tener el único acierto que desea. Además, la probabilidad de acierto sigue siendo la misma cada vez que le pregunta a un estudiante si vive a menos de cinco millas de usted. No hay un número definido de ensayos (número de veces que le pregunta a un estudiante).
a. Supongamos que X = el número de ______ a los que debe preguntar _____ uno dice que sí.
b. ¿Qué valores toma X?
c. ¿Qué son p y q?
d. La pregunta de probabilidad es P(_____).
Solución:
a. Supongamos que X = el número de estudiantes a los que debe preguntar hasta que uno diga que sí.
b. 1, 2, 3, …, (número total de estudiantes)
c. p = 0,55; q = 0,45
d. P(x = 4)
5. Distribución hipergeométrica
Hay cinco características de un experimento hipergeométrico.
- Se toman muestras de dos grupos.
- Le interesa un grupo de interés, llamado primer grupo.
- Se toma una muestra sin reemplazo de los grupos combinados. Por ejemplo, quiere elegir un equipo de softball entre un grupo combinado de 11 hombres y 13 mujeres. El equipo está formado por diez jugadores.
- Cada elección de un jugador no es independiente, ya que el muestreo es sin reemplazo. En el ejemplo del sóftbol, la probabilidad de elegir primero a una mujer es:
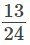
La probabilidad de elegir a un hombre en segundo lugar es:
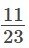
si se eligió a una mujer primero. Es
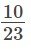
si se eligió a un hombre primero. La probabilidad de la segunda elección depende de lo que haya ocurrido en la primera.
5. No se trata de ensayos de Bernoulli.
Los resultados de un experimento hipergeométrico se ajustan a una distribución de probabilidad hipergeométrica. La variable aleatoria X = el número de elementos del grupo de interés.
Ejemplo:
Un plato de caramelos contiene 100 gominolas y 80 chicles. Se eligen 50 caramelos al azar. ¿Cuál es la probabilidad de que 35 de los 50 sean chicles? Los dos grupos son gominolas y pastillas de goma. Como la pregunta de probabilidad pide la probabilidad de seleccionar un chicle, el grupo de interés (primer grupo) es el de los chicles. El tamaño del grupo de interés (primer grupo) es de 80. El tamaño del segundo grupo es de 100. El tamaño de la muestra es de 50 (gominolas o chicles). Supongamos que X = el número de chicles en la muestra de 50. X toma los valores x = 0, 1, 2, …, 50. ¿Cuál es el enunciado de la probabilidad escrito matemáticamente?
Solución 1:
P(x = 35)
6. Distribución de Poisson
Hay dos características principales de un experimento de Poisson.
- La distribución de probabilidad de Poisson da la probabilidad de que se produzca un número de eventos en un intervalo fijo de tiempo o espacio si estos eventos se producen con una tasa promedio conocida y con independencia del tiempo transcurrido desde el último evento. Por ejemplo, un editor de libros podría estar interesado en el número de palabras escritas incorrectamente en un libro en particular. Puede ser que, en promedio, haya cinco palabras mal escritas en 100 páginas. El intervalo son las 100 páginas.
- La distribución de Poisson puede utilizarse para aproximarse a la binomial si la probabilidad de éxito es “pequeña” (del orden de 0,01) y el número de intentos es “grande” (del orden de 1000). Comprobará la relación en los ejercicios de los deberes. n es el número de intentos, y p es la probabilidad de un “acierto”.
La variable aleatoria X = el número de ocurrencias en el intervalo de interés.
Ejemplo:
Un banco espera recibir seis cheques sin fondos al día, en promedio. ¿Cuál es la probabilidad de que el banco reciba menos de cinco cheques sin fondos en un día determinado? El interés es el número de cheques que el banco recibe en un día, por lo que el intervalo de tiempo del interés es un día. Supongamos que X = el número de cheques sin fondos que recibe el banco en un día. Si el banco espera recibir seis cheques sin fondos al día, el promedio es de seis cheques al día. Escriba un enunciado matemático para la pregunta de probabilidad.
Solución:
P(x < 5)
Fuente y licenciamiento
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0