Introducción
Supongamos que intenta determinar el alquiler medio de un apartamento de dos habitaciones en su ciudad. Puede buscar en la sección de anuncios del periódico, anotar varios alquileres que aparezcan y hacer un promedio entre ellos. Habría obtenido una estimación puntual de la media real. Si intenta determinar el porcentaje de veces que encesta cuando lanza una pelota de baloncesto, puede contar el número de tiros que lo logra y dividirlo entre el número de tiros que intenta. En este caso, se habría obtenido una estimación puntual de la proporción real.
Utilizamos los datos de la muestra para hacer generalizaciones sobre una población desconocida. Esta parte de la Estadística se llama Estadística Inferencial. Los datos de la muestra nos ayudan a hacer una estimación de un parámetro de la población. Nos damos cuenta de que lo más probable es que la estimación puntual no sea el valor exacto del parámetro poblacional, sino que se acerque a él. Después de calcular las estimaciones puntuales, construimos las estimaciones de intervalo, llamadas intervalos de confianza.

En este capítulo aprenderá a construir e interpretar intervalos de confianza. También aprenderá una nueva distribución, la t de Student, y cómo se utiliza con estos intervalos. A lo largo del capítulo es importante tener en cuenta que el intervalo de confianza es una variable aleatoria. Es el parámetro poblacional que se fija.
Si usted trabajara en el departamento de mercadeo de una compañía de entretenimiento, podría interesarse por el número medio de canciones que un consumidor descarga al mes de iTunes. Si es así, puede hacer una encuesta y calcular la media muestral, x¯, y la desviación típica de la muestra, s. Usaría x¯ para estimar la media de la población y s para estimar la desviación típica de la población. La media muestral, x¯, es la estimación puntual de la media de la población, μ. La desviación típica de la muestra, s, es la estimación puntual de la desviación típica de la población, σ.
Cada uno de x¯ Cada y s se llama estadística.
Un intervalo de confianza es otro tipo de estimación pero, en vez de ser un solo número, es un intervalo de números. Proporciona un rango de valores razonables en el que esperamos que se ubique el parámetro de la población. No hay garantía de que un determinado intervalo de confianza capte el parámetro, pero hay una probabilidad de éxito predecible.
Supongamos, para el ejemplo de iTunes, que no conocemos la media poblacional μ, pero sí sabemos que la desviación típica de la población es σ = 1 y que nuestro tamaño de muestra es 100. Entonces, por el teorema del límite central, la desviación típica para la media de la muestra es
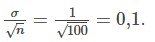
La regla empírica, que se aplica a las distribuciones en forma de campana, dice que en aproximadamente el 95 % de las muestras, la media muestral, x¯x¯, estará dentro de las dos desviaciones típicas de la media poblacional μ. Para nuestro ejemplo de iTunes, dos desviaciones típicas son (2)(0,1) = 0,2. La media muestral x¯x¯ es probable que esté dentro de 0,2 unidades de μ.
Dado que x¯x¯ está dentro de 0,2 unidades de μ, que es desconocido, entonces es probable que μ esté dentro de 0,2 unidades de x¯x¯ en el 95 % de las muestras. La media poblacional μ está contenida en un intervalo cuyo número inferior se calcula tomando la media muestral y restando dos desviaciones típicas (2)(0,1) y cuyo número superior se calcula tomando la media muestral y sumando dos desviaciones típicas. En otras palabras, μ está entre x¯ – 00,2x¯ – 00,2 y x¯ + 00,2x¯ + 00,2 en el 95 % de las muestras.
Para el ejemplo de iTunes, supongamos que una muestra produce una media muestral x¯ = 2x¯ = 2. Entonces la media poblacional desconocida μ está entre
x¯–0,2=2–0,2=1,8x¯–0,2=2–0,2=1,8 y x¯+0,2=2+0,2=2,2x¯+0,2=2+0,2=2,2
Decimos que tenemos un 95 % de confianza en que la media de la población desconocida de canciones descargadas de iTunes al mes está entre 1,8 y 2,2. El intervalo de confianza del 95 % es (1,8; 2,2).
El intervalo de confianza del 95 % implica dos posibilidades. O bien el intervalo (1,8, 2,2) contiene la verdadera media μ o nuestra muestra produjo un x¯x¯ que no esté a menos de 0,2 unidades de la media verdadera μ. La segunda posibilidad solo se da en el 5 % de las muestras (95 a 100 %).
Recuerde que un intervalo de confianza se crea para un parámetro poblacional desconocido como la media poblacional, μ. Los intervalos de confianza para algunos parámetros tienen la forma:
(estimación puntual – margen de error, estimación puntual + margen de error)
El margen de error depende del nivel o porcentaje de confianza y del error estándar de la media.
Cuando lea los periódicos y revistas, algunos informes utilizarán la frase “margen de error”. Otros informes no utilizan esa frase, sino que incluyen un intervalo de confianza como la estimación puntual más o menos el margen de error. Son dos formas de expresar el mismo concepto.
La media de una población utilizando la distribución normal
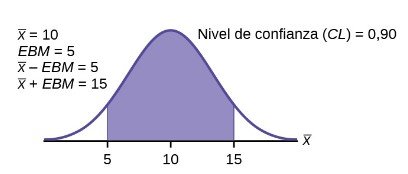
Un intervalo de confianza para una media poblacional con una desviación típica poblacional conocida se basa en la conclusión del teorema del límite central de que la distribución muestral de las medias muestrales sigue una distribución aproximadamente normal. Supongamos que nuestra muestra tiene una media de x¯ = 10x¯ = 10 y hemos construido el intervalo de confianza del 90 % (5, 15) donde EBM = 5.
Cálculo del intervalo de confianza
Para construir un intervalo de confianza para una única media poblacional desconocida μ, cuando se conoce la desviación típica de la población, necesitamos x¯x¯ como una estimación de μ y necesitamos el margen de error. Aquí, el margen de error (EBM) se denomina límite de error para una media poblacional (abreviado EBM). La media muestral x¯x¯ es la estimación puntual de la media poblacional desconocida μ.
La estimación del intervalo de confianza tendrá la forma:
(estimación puntual – límite de error, estimación puntual + límite de error) o, en símbolos, (x¯–EBM,x¯+EBMx¯–EBM,x¯+EBM)
El margen de error (EBM) depende del nivel de confianza (Confidence Level, CL). El nivel de confianza suele considerarse la probabilidad de que la estimación del intervalo de confianza calculado contenga el verdadero parámetro poblacional. Sin embargo, es más preciso afirmar que el nivel de confianza es el porcentaje de intervalos de confianza que contienen el verdadero parámetro de la población cuando se toman muestras repetidas. La mayoría de las veces, la persona que construye el intervalo de confianza elige un nivel de confianza del 90 % o superior porque quiere estar razonablemente segura de sus conclusiones.
Existe otra probabilidad llamada alfa (α). α está relacionada con el nivel de confianza, CL. α es la probabilidad de que el intervalo no contenga el parámetro poblacional desconocido.
Matemáticamente, α + CL = 1.
Un intervalo de confianza para una media poblacional con una desviación típica conocida se basa en el hecho de que las medias muestrales siguen una distribución aproximadamente normal. Supongamos que nuestra muestra tiene una media de x¯ = 10, y hemos construido el intervalo de confianza del 90 % (5, 15) donde EBM = 5.
Para obtener un intervalo de confianza del 90 %, debemos incluir el 90 % central de la probabilidad de la distribución normal. Si incluimos el 90 % central, dejamos fuera un total de α = 10 % en ambas colas, o 5 % en cada cola, de la distribución normal.
Para captar el 90 % central, debemos salir 1,645 “desviaciones típicas” a cada lado de la media muestral calculada. El valor 1,645 es la puntuación z de una distribución de probabilidad normal estándar que sitúa un área de 0,90 en el centro, un área de 0,05 en la cola extrema izquierda y un área de 0,05 en la cola extrema derecha.
Es importante que la “desviación típica” utilizada sea la adecuada para el parámetro que estamos estimando, por lo que en este apartado debemos utilizar la desviación típica que se aplica a las medias muestrales, que es
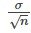
La fracción:
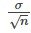
Se denomina comúnmente “error estándar de la media” para distinguir claramente desviación típica de una media de la desviación típica de la población σ.
En resumen, como resultado del teorema del límite central:

Cálculo del intervalo de confianza
Para construir una estimación de intervalo de confianza para una media poblacional desconocida necesitamos datos de una muestra aleatoria. Los pasos para construir e interpretar el intervalo de confianza son:
- Calcular la media muestral x¯ de los datos de la muestra. Recuerde que en esta sección ya conocemos la desviación típica de la población σ.
- Calcule la puntuación z que corresponde al nivel de confianza.
- Calcular el límite de error EBM.
- Construir el intervalo de confianza.
- Escriba una oración que interprete la estimación en el contexto de la situación del problema. (Explique lo que significa el intervalo de confianza, en las palabras del problema).
Primero examinaremos cada paso con más detalle y luego ilustraremos el proceso con algunos ejemplos.
Calcular la puntuación z para el nivel de confianza declarado
Cuando conocemos la desviación típica de la población σ, utilizamos una distribución normal estándar para calcular el EBM y construir el intervalo de confianza. Necesitamos hallar el valor de z que pone un área igual al nivel de confianza (en forma decimal) en el centro de la distribución normal estándar Z ~ N(0, 1).
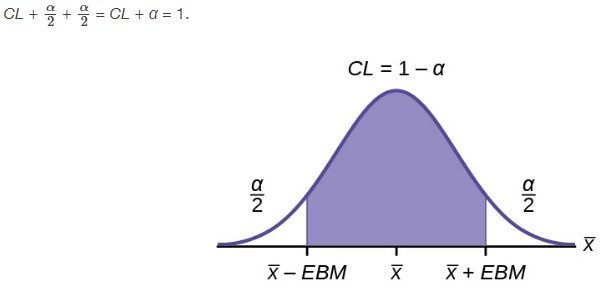
El nivel de confianza, CL, es el área en el medio de la distribución normal estándar. CL = 1 – α, por lo que α es el área que se divide por igual entre las dos colas. Cada

Cálculo del límite de error (EBM)
La fórmula del límite de error para una media poblacional desconocida μ cuando se conoce la desviación típica poblacional σ es
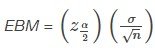
Construcción del intervalo de confianza
La estimación del intervalo de confianza tiene el formato (x¯–EBM,x¯+EBM). El gráfico da una idea de toda la situación.
Redacción de la interpretación
La interpretación debe indicar claramente el nivel de confianza (CL), explicar qué parámetro de la población se está estimando (en este caso, una media de la población), e indicar el intervalo de confianza (ambos puntos finales). “Estimamos con un % de confianza que la verdadera media de la población (incluya el contexto del problema) está entre y _ (incluya las unidades adecuadas)”.
Ejemplo:
Supongamos que las puntuaciones de los exámenes de estadística se distribuyen normalmente con una media poblacional desconocida y una desviación típica de la población de tres puntos. Se toma una muestra aleatoria de 36 puntuaciones y se obtiene una media muestral (puntuación media de la muestra) de 68. Calcule una estimación del intervalo de confianza para la calificación media del examen de la población (la calificación media de todos los exámenes).
Calcular un intervalo de confianza del 90 % para la media real (poblacional) de las calificaciones de los exámenes de Estadística.
Solución

Hacer el cálculo a la inversa para calcular el límite de error o la media de la muestra
- Cuando calculamos un intervalo de confianza, encontramos la media de la muestra, calculamos el límite de error y lo utilizamos para calcular el intervalo de confianza. Sin embargo, a veces, cuando leemos estudios estadísticos, el estudio puede indicar solo el intervalo de confianza. Si conocemos el intervalo de confianza, podemos hacer el cálculo a la inversa para hallar tanto el límite de error como la media de la muestra.
Calcular el límite de error
- Del valor superior del intervalo, reste la media de la muestra.
- O, del valor superior del intervalo, reste el valor inferior. A continuación, divida la diferencia entre dos.
Calcular la media de la muestra
- Reste el límite de error del valor superior del intervalo de confianza.
- O, promedie los puntos finales superior e inferior del intervalo de confianza.
Observe que hay dos métodos para realizar cada cálculo. Puede elegir el método que sea más fácil de utilizar con la información que conoce.
Ejemplo:

Cálculo del tamaño de la muestra n
Si los investigadores desean un margen de error específico, pueden utilizar la fórmula del límite de error para calcular el tamaño necesario de la muestra.
La fórmula del límite de error para una media poblacional cuando se conoce la desviación típica de la población es
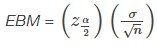
La fórmula del tamaño de la muestra es
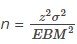
que se encuentra resolviendo la fórmula del límite de error para n.
En esta fórmula, z es
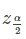
Correspondiente al nivel de confianza deseado. Un investigador que planifique un estudio y desee un nivel de confianza y un límite de error específicos puede utilizar esta fórmula para calcular el tamaño de la muestra necesaria para el estudio.
Ejemplo:

La media de una población utilizando la distribución t de estudiante
En la práctica, pocas veces conocemos la desviación típica de la población. En el pasado, cuando el tamaño de la muestra era grande, esto no suponía un problema para los estadísticos. Utilizaron la desviación típica de la muestra s como una estimación de σ y procedieron como antes para calcular un intervalo de confianza con resultados suficientemente cercanos. Sin embargo, los estadísticos se encontraron con problemas cuando el tamaño de la muestra era pequeño. El pequeño tamaño de la muestra provocó imprecisiones en el intervalo de confianza.
William S. Goset (1876-1937), de la fábrica de cerveza Guinness de Dublín (Irlanda), se encontró con este problema. Sus experimentos con lúpulo y cebada produjeron muy pocas muestras. La simple sustitución de σ por s no produjo resultados precisos cuando intentó calcular un intervalo de confianza. Se dio cuenta de que no podía utilizar una distribución normal para el cálculo; descubrió que la distribución real depende del tamaño de la muestra. Este problema lo llevó a “descubrir” lo que se llama la distribución t de Student. El nombre proviene del hecho de que Gosset escribió bajo el seudónimo de “Student”.
Hasta mediados de los años 70, algunos estadísticos utilizaban la aproximación de la distribución normal para tamaños de muestra grandes y utilizaban la distribución t de estudiante solo para tamaños de muestra de como máximo 30. Con las calculadoras gráficas y las computadoras, la práctica actual es utilizar la distribución t de estudiante siempre que se utilice s como estimación de σ.
Si se extrae una muestra aleatoria simple de tamaño n de una población que tiene una distribución aproximadamente normal con media μ y desviación típica poblacional desconocida σ y se calcula la puntuación
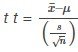
entonces las puntuaciones t siguen una distribución t de Student con n – 1 grados de libertad. La puntuación tt iene la misma interpretación que la puntuación z. Mide cuán lejos está x¯x¯ es de su media μ. Para cada tamaño de muestra n existe una distribución t de Student diferente.
Los grados de libertad, n – 1, proceden del cálculo de la desviación típica de la muestra s. En el H – TABLAS, utilizamos n desviaciones (x–x¯valores)(x–x¯valores) para calcular s. Como la suma de las desviaciones es cero, podemos hallar la última desviación una vez que conocemos las otras n – 1 desviaciones. Las otras n – 1 desviaciones pueden cambiar o variar libremente. Llamamos al número n – 1 los grados de libertad (df).
Propiedades de la distribución t de Student
- El gráfico de la distribución t de Student es similar a la curva normal estándar.
- La media de la distribución t de Student es cero y la distribución es simétrica con respecto a cero.
- La distribución t de Student tiene más probabilidad en sus colas que la distribución normal estándar porque la dispersión de la distribución t es mayor que la dispersión de la normal estándar. Así, el gráfico de la distribución t de Student será más gruesa en las colas y más corta en el centro que el gráfico de la distribución normal estándar.
- La forma exacta de la distribución t de Student depende de los grados de libertad. A medida que aumentan los grados de libertad, el gráfico de la distribución t de Student se parece más al gráfico de la distribución normal estándar.
- Se supone que la población subyacente de observaciones individuales se distribuye normalmente, con una media poblacional desconocida μ y una desviación típica poblacional desconocida σ. El tamaño de la población subyacente no suele ser relevante, a menos que sea muy pequeña. Si tiene forma de campana (normal), la hipótesis se cumple y no es necesario discutirla. Se supone que el muestreo es aleatorio, pero ese es un supuesto completamente distinto de la normalidad.
Las calculadoras y las computadoras pueden calcular fácilmente cualquier probabilidad t de Student. Las TI-83,83+ y 84+ tienen una función tcdf para calcular la probabilidad para valores dados de t. La gramática del comando tcdf es tcdf (límite inferior, límite superior, grados de libertad). Sin embargo, para los intervalos de confianza, necesitamos utilizar la probabilidad inversa para calcular el valor de t cuando conocemos la probabilidad.
Para la TI-84+ puede utilizar el comando invT del menú DISTRibution. El comando invT funciona de forma similar al invnorm. El comando invT requiere dos entradas: invT (área a la izquierda, grados de libertad). La salida es la puntuación t que corresponde al área que especificamos.
Las TI-83 y 83+ no tienen el comando invT (la TI-89 tiene un comando T inverso).
También se puede utilizar una tabla de probabilidad para la distribución t de estudiante La tabla muestra las puntuaciones t que corresponden al nivel de confianza (columna) y los grados de libertad (fila). (la TI-86 no tiene un programa o comando invT, por lo que si está utilizando esa calculadora, deberá utilizar una tabla de probabilidad para la distribución t de estudiante) Al utilizar una tabla t, tenga en cuenta que algunas tablas están formateadas para mostrar el nivel de confianza en los títulos de las columnas, mientras que los títulos de las columnas de algunas tablas pueden mostrar solo el área correspondiente en una o ambas colas.
Una tabla t de estudiante da las puntuaciones t dados los grados de libertad y la probabilidad de cola derecha. La mesa es muy limitada. Las calculadoras y las computadoras pueden calcular fácilmente cualquier probabilidad t de estudiante.
La notación para la distribución t de Student (utilizando T como variable aleatoria) es:
- T ~ tdf donde df = n – 1.
- Por ejemplo, si tenemos una muestra de tamaño n = 20 elementos, entonces calculamos los grados de libertad como df = n – 1 = 20 – 1 = 19 y escribimos la distribución como T ~ t19.
Si no se conoce la desviación típica de la población, el límite de error para una media poblacional es:

Fuente y licenciamiento
- OpenStax (2022). Introducción al estadística. OpenStax https://openstax.org/books/introducci%C3%B3n-estad%C3%ADstica/
- De OpenStax bajo licencia Creative Commons Attribution License v4.0