Introducción
La estadística descriptiva te permite obtener conclusiones sobre un conjunto de datos y sólo sobre ese conjunto de datos (la muestra). De manera muy sencilla, la Estadística descriptiva incluye técnicas para recolectar, presentar, analizar e interpretar una masa de datos. En cambio, la Estadística inferencial incluye un conjunto de técnicas para obtener conclusiones que sobrepasan los límites de los conocimientos aportados por la muestra y busca explicar a partir de ellos cómo se comporta la población.

Medidas de tendencia central para datos no agrupados
Aunque una distribución de frecuencias y su representación gráfica son verdaderamente muy útiles para tener una idea global del comportamiento que presentan los datos, es también necesario resumirlos aún más calculando algunas medidas descriptivas. Estas medidas son valores que se interpretan fácilmente y sirven para realizar un análisis más profundo y detallado que el obtenido por los resúmenes tabulares y gráficos.
Promedio
Los promedios son una medida de posición que dan una descripción compacta de cómo están centrados los datos y una visualización más clara del nivel que alcanza la variable, pueden servir de base para medir o evaluar valores extremos o raros y brinda mayor facilidad para efectuar comparaciones.
El promedio como un valor representativo de los datos es el valor alrededor del cual se agrupan los demás valores de la variable. Se dice que los datos estadísticos no están de forma agrupada cuando no se encuentran resumidos en tablas de distribución de frecuencias.
Se iniciará con las llamadas medidas de localización, es decir, medidas que buscan cierto lugar del conjunto de datos; cuando el lugar buscado es el centro de los datos les llamamos medidas de tendencia central de las cuales considerarán: la media, la moda y la mediana.
La media, la mediana y la moda son estadígrafos de tendencia central.
La media aritmética
La media aritmética es el promedio que resulta de sumar el valor de todos los datos y dividirlo entre el número de datos.
En la media aritmética el valor de cada uno de los datos cuenta; esa es su principal ventaja. Por otro lado, tiene como principal desventaja que es muy sensible a los valores extremos. ¿Qué quiere decir eso?
Supón que te piden sacar el promedio de edad de Luis, Pepe y Laura. Cada uno de ellos tiene 15 años:
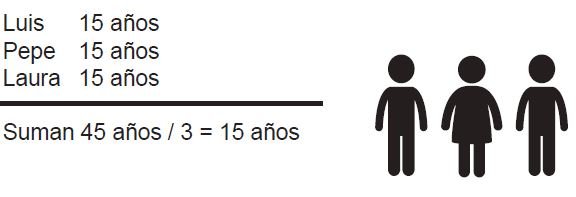
Supón ahora que te piden sacar el promedio de edad de:
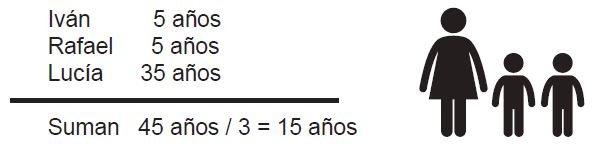
Como puedes ver, en los dos casos la media aritmética es de 15 años, pero en el segundo la edad de Lucía eleva mucho el promedio. Por esto se dice que la media aritmética es sensible a valores extremos. Como se puede observar en el ejemplo, un solo dato con valor muy alejado del centro, aunque sea poco representativo por ser único, puede hacer variar significativamente el promedio.
La gran sensibilidad de la media aritmética a valores extremos tiene impactos importantes en las ciencias. Por ejemplo, tomó mucho a los economistas dar cuenta de que el ingreso por habitante (ingreso total del país entre el número de habitantes
de ese país) no es un indicador suficiente de desarrollo económico, si existe una mala distribución del ingreso.
Otro ejemplo lo constituye la esperanza promedio de vida al nacer (edad promedio de vida de los habitantes de un país). Indicador que en México pasó de 39.8 años en 1940 a más de 75 actualmente. El drástico aumento de este indicador se explica por la importante disminución de la mortalidad infantil entre cero y cinco años.
Características de la Media:
- En su cálculo están todos los valores del conjunto de datos por lo que cada uno afecta a la media.
- La suma de las desviaciones de los valores individuales respecto a la media es cero.
- Aunque es confiable porque refleja todos los valores del conjunto de datos, puede ser afectada por los valores extremos, y de esa forma llega a ser una medida menos representativa, por lo que si la distribución es sesgada, la media aritmética no constituye un valor representativo.
La mediana
En la mediana, a diferencia de la media aritmética, no cuenta el valor de cada dato. Únicamente cuenta el valor de uno solo: el dato que divide la lista en dos mitades exactamente iguales.
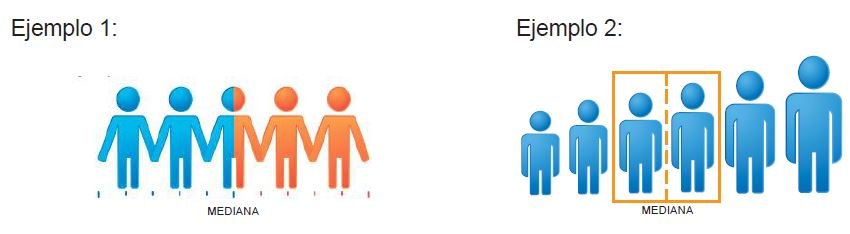
- En el ejemplo 1, como se trata de un número impar de cifras; la mediana será la persona que ocupa la posición 3.
- En el ejemplo 2, como se trata de un número par de cifras, la mediana será el promedio de edades de las personas que ocupan las dos posiciones contiguas.
Cuando determinados valores de un conjunto de observaciones son muy grandes o pequeños con respecto a los
demás, entonces la media aritmética se puede distorsionar y perder su carácter representativo, en esos casos es
conveniente utilizar la mediana como medida de tendencia central.
Características de la mediana:
- Es un promedio de posición no afectado por los valores extremos.
- La mediana en caso de una distribución sesgada, no resulta desplazada del punto de tendencia central.
Cuartiles, deciles y percentiles
Además de la mediana, existen otros estadígrafos que te permiten dividir tus datos ordenados en partes.
- a) Si divides tus datos en cuatro partes se llaman cuartiles. (Q)
- b) Si los divides en diez partes, deciles. (D)
- c) Si lo haces en cien partes, percentiles. (P)
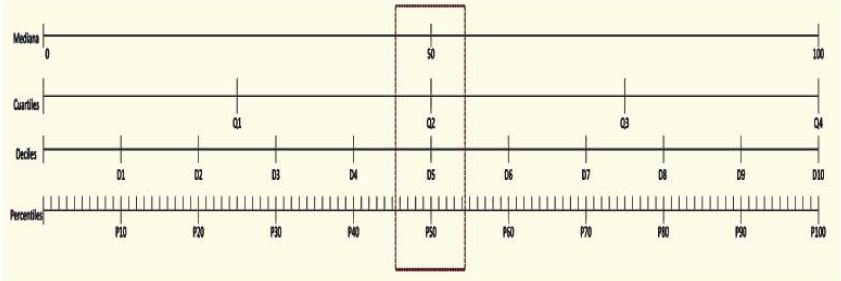
Como puedes ver en el gráfico de arriba, la mediana, el segundo cuartil, el quinto decil y el 50 percentil, tienen el mismo valor.
La moda
La moda de un conjunto de n observaciones x1, x2, . . . ,xn es el valor que se repite con mayor frecuencia. Se puede simbolizar con x. Se considera el valor más típico de una serie de datos. La moda puede no existir o no ser única, las distribuciones que presentan dos o más máximos relativos se designan de modo general como bimodales o multimodales.
La moda es el valor que ocurre más frecuentemente en una distribución organizada de datos; es el valor que está de moda.
La moda puede no existir e incluso puede no ser única. Cuando hay dos modas en un conjunto de datos, se le llama conjunto bimodal; cuando hay más, multimodal.
Características de la Moda:
- Representa más elementos que cualquier otro valor
- La moda no permite conocer la mayor parte de los datos
- Puede usarse para datos cuantitativos como cualitativos
- La moda como estadístico, varía mucho de una muestra a otra
- Cuando se tienen dos o más modas es difícil su interpretación
A continuación te presentamos tres representaciones gráficas de la moda.
Relaciones empíricas entre la media, la mediana y la moda
En una distribución simétrica el valor de la media aritmética, la mediana y la moda coinciden.
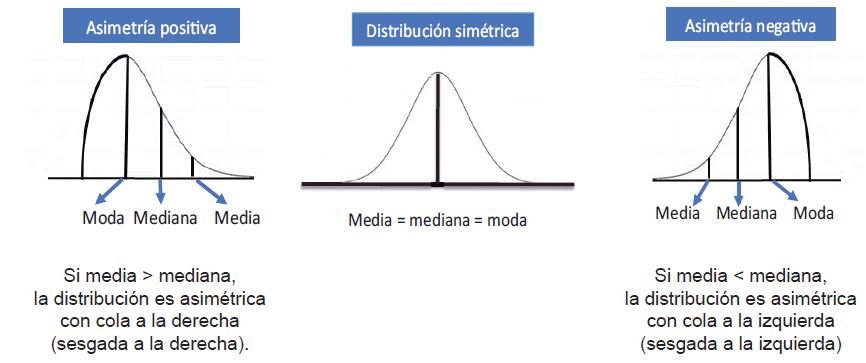
Para curvas de frecuencia unimodales poco asimétricas existe la siguiente relación empírica: Media – moda = 3 (media – mediana). Esto quiere decir que, en estos casos, la diferencia entre la media y la mediana es tres veces menor a la que existe
entre la media y la moda.
Estadígrafos de dispersión
Hasta aquí los estadígrafos de tendencia central. Ya conoces la media, la mediana y la moda, y sabes que son medidas que pueden representar a un conjunto de datos. Demos el siguiente paso:
Vamos a conocer ahora qué tan representativas son estas medidas de su conjunto de datos. Para ello se utilizan los estadígrafos de dispersión, que vamos ahora a trabajar.
Los estadígrafos de dispersión pueden ser:
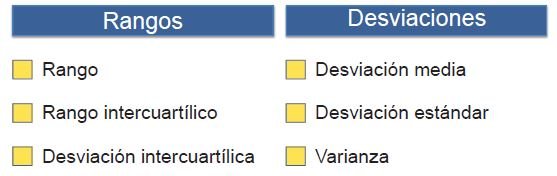
Como puedes ver en el cuadro, los primeros instrumentos que nos pueden ayudar a saber qué tan dispersa está la información con la que contamos son los rangos.
Rangos
El rango propiamente dicho mide la distancia que existe entre el mayor y el menor de los datos de un conjunto.
Dado que, en el cuadro de edades de tu comunidad, el mayor de los datos es el 43 y el menor el 2, el rango es igual a __________
Por su parte, el rango intercuartílico mide la distancia entre el valor del cuartil 3 y del cuartil 1. Esto quiere decir que no considera la dispersión de todos los datos de un conjunto, sino únicamente la que existe entre los valores de Q3 y Q1.
Como tú ya calculaste los valores de Q3 y Q1 páginas arriba, te pedimos ahora que calcules rango intercuartílico = Q3 – Q1
Q3 – Q1 = _____________
En el cuadro siguiente puedes apreciar la diferencia entre el rango y el rango intercuartílico:
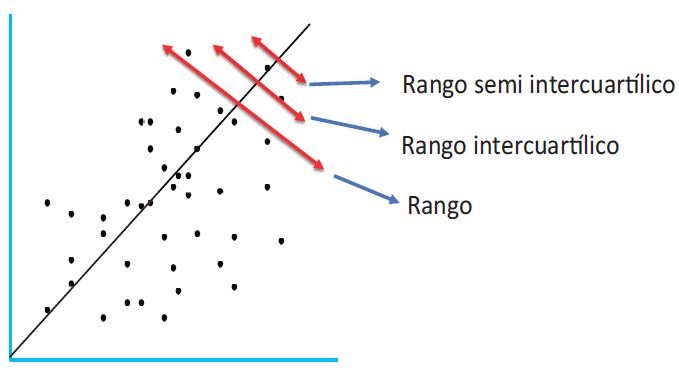
Como puedes observar en el ejemplo de arriba, la ventaja del rango consiste en que incluye todas las observaciones. Sin embargo, su desventaja es que es muy sensible a la existencia de valores extremos. En cambio, aunque el rango intercuartílico únicamente considera la mitad del trayecto entre el dato mayor y el dato menor, evitando el sesgo de los valores extremos.
Existe un tercer rango que es aún más preciso: el rango semi intercuartílico. Si ves su fórmula lo vas a entender perfectamente.
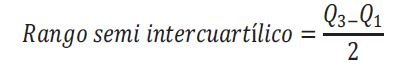
Como verás en el gráfico este rango considera la mitad de las observaciones que el rango intercuartílico. Para interpretar correctamente los rangos intercuartílicos y semi intercuartílicos es necesario que recuerdes que los cuartiles son estadígrafos de posición. Esto quiere decir que pueden darse situaciones como la siguiente:
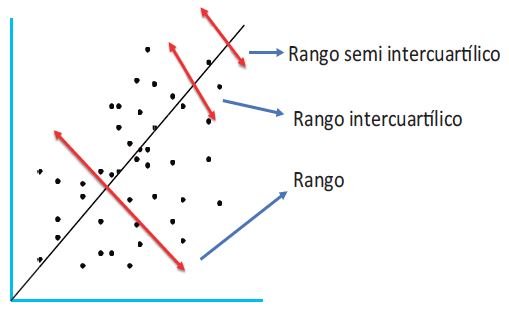
En las que las distancias entre Q3 y Q1 no son simétricas alrededor de la media.
Desviaciones
Los rangos que hemos visto no utilizan todos los datos de un conjunto para medir la dispersión. Lejos de ello, utiliza sólo dos datos. En el caso del rango propiamente dicho, únicamente los valores mayor y menor de un conjunto de datos; y en los casos de los rangos intercuartílico y semi intercuartílico los valores de Q3 y Q1.
En cambio, las tres desviaciones, como veremos a continuación: la desviación media, la desviación estándar y la varianza, se calculan comparando las diferencias de los valores de todos y cada uno de los datos de un conjunto respecto la media aritmética que tú conoces muy bien.
¡Sólo que tenemos un problema!
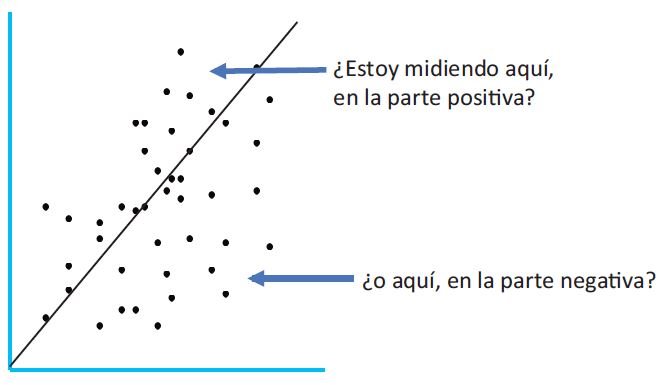
Como puedes ver en el siguiente gráfico, unos datos quedan por encima de la media y otros por debajo. Para cada dato por encima de la media, su diferencia respecto a ella será positiva. Y para el dato por debajo de la media; negativa.
El problema que tenemos es que si sumamos todas las diferencias positivas y les restamos las negativas, se compensan y dan cero para cualquier distribución de frecuencias.
Y entonces, obtener siempre cero como resultado no nos sirve de nada.
De hecho, cada una de las tres desviaciones que mencionamos: la desviación media, la desviación estándar y la varianza, se distinguen por la manera en que resuelve este problema; ¡veámos cómo le hacen! Ya vimos que la suma de las diferencias entre cada dato y la media siempre da cero.
En lenguaje matemático eso se escribe así:
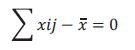
Donde:

La primera manera de romper el cero es quitándole el signo a las diferencias entre cada dato y la media. Eso se llama manejar valores absolutos y se escribe así:
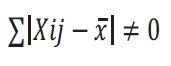
Donde:

Si el resultado obtenido lo dividimos entre el número de datos de un conjunto se llama desviación media:
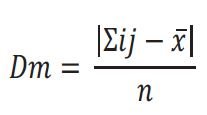
Donde:

Los enemigos de la desviación media la critican diciendo que al quitar los signos a la diferencia entre los datos y la media ya no se sabe si estamos midiendo la dispersión en la parte de arriba o de abajo de la distribución de frecuencias.
Por lo tanto, hacen una segunda propuesta para romper el cero:
Como se eleva al cuadrado cualquier número negativo se vuelve positivo hay que elevar al cuadrado las diferencias de cada dato respecto a la media, y luego sacarle raíz cuadrada por eso estos críticos dicen que hay que sacarle raíz cuadrada para no alterar la ecuación.
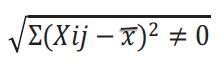
Esta es la propuesta de la desviación estándar:
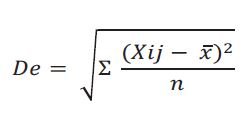
Donde:

Es una buena solución, ¿no te parece? ¡A nosotros también!
Sin embargo, como siempre ocurre, hay quienes pre eren una tercera manera de romper el cero, porque no les gusta la raíz cuadrada de la fórmula anterior. Para quitarla, proponen elevar al cuadrado los dos lados de la ecuación de la desviación estándar:
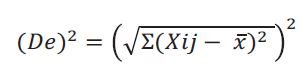
que es igual a:
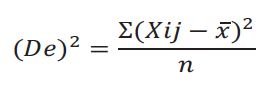
En donde:

La desviación estándar y la varianza están muy relacionadas. La primera es la raíz cuadrada de la segunda.
En cambio, el rango intercuartílico, la desviación media y la desviación estándar difieren de tamaño.
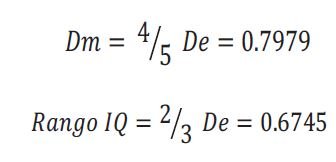
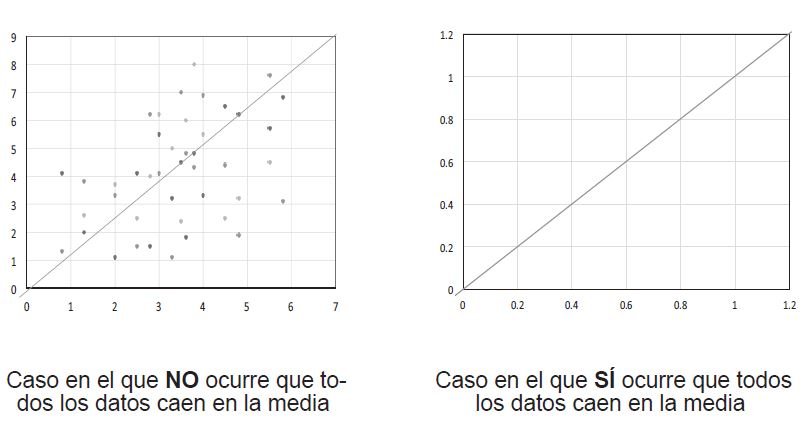
Sólo en el caso de que todos los datos cayeran sobre la media, todos los rangos y las desviaciones serían iguales, y su valor sería cero.
Ejemplo:
Fuentes: Secretaría de Educación Pública. (2015). Probabilidad y estadística I. Ciudad de México. / Colegio de Bachilleres del Estado de Sonora. (2016). Probabilidad y Estadística I. Sonora, México.