Variables aleatorias continuas y discretas y su aplicación en las distribuciones de probabilidad
Un juego de futbol puede ser considerado como un experimento aleatorio, en que solo existen dos posibles resultados: ganar o perder. Retomando la definición de variable aleatoria, asignamos un valor a los posibles resultados con el objetivo de establecer una probabilidad.

Asimismo una variable aleatoria debe tener conjunto de valores posibles y una probabilidad definible asociada con valor. En general, representamos la variable aleatoria por X, y un valor determinado del dominio de la variable aleatoria X por una x.
Debemos tener presente que las variables aleatorias se representan usualmente con las ultimas letras del alfabeto mayúsculas (X, Y, Z) y los valores que puede tomar se reconocerán con minúsculas (x, y, z). De la misma forma, identificaremos el espacio muestral con la letra S, y definiendo este último como la serie de resultados individuales en un experimento.
Como recordarás, las variables aleatorias se clasifican en dos tipos: discretas y continuas:
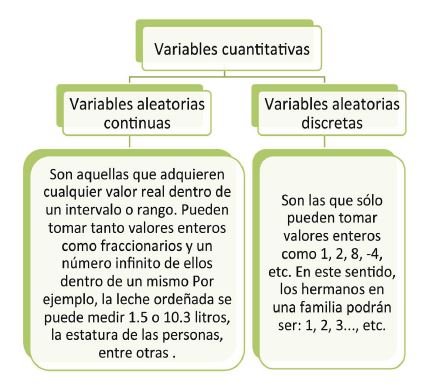
Las variables aleatorias (discretas y continuas) se hacen presentes al ocurrir, una distribución como parte de un comportamiento matemático, es decir, se especifican los valores posibles y el de las respectivas probabilidades asociadas a un espacio muestral.
Es común que el valor de una variable dependa del de otra. Por ejemplo, el ingreso de un trabajador pude depender del tiempo que trabaje; la producción de una fábrica puede depender del número de máquinas que se utilicen; la distancia recorrida por un objeto pude depender de la velocidad con que se desplace.
La relación entre este tipo de cantidades de variables, suele expresarse mediante una función:
Si a cada valor “x” que puede tomar una variable X le corresponde un valor “y” de otra variable Y, decimos que “y” es función de “x”, donde el número “y” es único para cada valor de “x”.
El conjunto de todos los valores que puede tomar x se le llama dominio de la función y al conjunto de todos los valores resultantes de y se le denomina contradominio de la función.
Función y distribución de probabilidad
La función de los valores numéricos de x la representamos por f(x), g(x), r(x), etc. y la probabilidad de que la variable aleatoria X tome el valor x con P(X = x ).
Así, sean x1, x2, …, xn (espacio muestral de X), los valores para los cuales X tiene probabilidad y sean p1, p2 ,…, pn las probabilidades correspondientes. Entonces P(X = x1) = p1. Bajo este criterio podemos decir que:
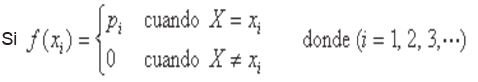
A f(xi) se le llama función de probabilidad. La función de probabilidad debe satisfacer las siguientes propiedades:
- f (xi) ≥ 0
- S f(xi) = 1
A partir de la función de probabilidad podemos establecer el concepto de distribución de probabilidad en la forma siguiente:
La distribución de probabilidad de una variable aleatoria discreta se presenta como la lista de los distintos valores xi que puede tomar la variable aleatoria X, junto con sus probabilidades asociadas f(xi) = P(X = xi), esto es, el conjunto de parejas {xi,
f(xi)}.
Cuando determinamos los valores de la variable aleatoria, le asignamos una probabilidad, y a esto se le llama distribución de probabilidad.
Distribución de probabilidad
Las distribuciones probabilidad revelan un gran número de valores que pueden constituirse como el resultado de un experimento. En otras palabras, nos ayudan a describir la probabilidad de que un evento se realice a futuro; esto involucra el
diseño de escenarios de acontecimientos futuros posibles. Comúnmente son utilizadas como parte de las tendencias posibles en que ocurran distintos resultados, como en el caso de algunos fenómenos naturales, como la situación del clima en un día, si llueve o será soleado, por ejemplo.
En el apartado anterior analizaste una clasificación en distribuciones de probabilidad de variables aleatorias discretas y continuas. A su vez, existe la posibilidad de que como parte de la distribución de probabilidad, las variables discretas sean clasificadas como:
- Distribución uniforme
- Simétrica
- Binomial hipergeométrica y,
- de Poisson.
En cambio otras posibilidades de clasificar la distribución de probabilidad de variables continuas son dos:
• Distribución normal y,
• Exponencial
Para efectos de este curso, de las opciones mencionadas, únicamente estudiaremos la distribución binomial y la distribución normal debido a sus amplias posibilidades de aplicación. Una manera común de enfocar a partir de la distribución de probabilidad es a través de enumerar los posibles resultados que pudieran resultar de la elaboración de un experimento.
No olvides que una distribución de probabilidad siempre es la suma de todas las funciones posibles (f(x) = 1), por lo que la sumatoria siempre tiene que ser igual al espacio muestral; esto es (f(x) = 100%).
Distribución de probabilidad binomial
A lo largo de este curso se ha reiterado que una distribución de probabilidad indica toda la gama de valores que pueden representarse como resultado de un experimento si éste se llevase a cabo, es decir, describe la probabilidad de que un evento se realice en el futuro, y por ello constituye una herramienta fundamental para diseñar un escenario de acontecimientos próximos a suceder, considerando las tendencias actuales de diversos fenómenos naturales.
En el estudio de la Probabilidad y la Estadística es común asociar el tema de la distribución binomial o distribución de Bernoulli con el matemático suizo Jacobo Bernoulli quien hizo grandes aportaciones a finales del siglo XVII. Una de las más importantes tiene que ver con el método que mide el número de éxitos que tendrá una secuencia de ensayos (n).
Su relevancia se liga a las múltiples áreas de aplicación de ésta distribución, por ejemplo, en la inspección de calidad de productos, ventas, mercadotecnia, medicina, investigación de opiniones y otras.
Cuando realizamos esta clase de mediciones se puede planear un experimento en que el resultado es la ocurrencia o la no ocurrencia de un evento. También se denomina éxito a la ocurrencia del evento y fracaso a la no ocurrencia del mismo.
Para poder denominarse como binomial, una distribución de eventos debe cumplir con algunas condiciones:
Se asocia frecuentemente con variables aleatorias discretas en que se determina el número de éxitos de una muestra compuesta; por ende, las observaciones, resultados, éxitos son representados a través de la letra n que significa el número de veces que se realiza un experimento.
- La información con variables aleatorias debe componerse de números fijos, es decir enteros.
- Cuando tenemos una serie de datos, estos pueden ser clasificados en dos distintas categorías: mutuamente excluyentes y colectivamente exhaustivos.
- La probabilidad de que el número de éxitos, resultados u observaciones se clasifique como un éxito es constante entre un resultado al otro. Por otra parte, la probabilidad de que un resultado sea un fracaso es constante en todos los resultados.
Ejemplo
La fórmula que utilizaremos para obtener la distribución binomial es la siguiente:

Anteriormente se mencionó que las distribuciones de probabilidad siempre son la suma de todas las funciones posibles ((f(x) = 1), por lo que su sumatoria siempre tiene que ser igual al espacio muestral; esto es (f(x) = 100%). Comprobemos si esta regla se cumple al analizar el siguiente ejercicio:

Distribución de probabilidad normal estándar
La normal estándar, es de las distribuciones de probabilidad, la más importante, ayuda a administrar muchos fenómenos, pues varias poblaciones tienen distribución normal o pueden ajustarse muy bien a ella. Esta clase de distribución es comúnmente utilizada en el campo de la industria cuando se tiene una muestra grande.
Se identifica a través de una curva simétrica. Esta gráfica también recibe el nombre distribución o campana de Gauss, pues al representar su función de probabilidad, tiene forma de campana.
El profesor Julio Vargas (2010) afirma que esta distribución nos da la probabilidad de que al elegir un valor, éste tenga una medida contenida en unos intervalos definidos. Esto permitirá predecir de forma aproximada, el comportamiento futuro de un proceso, mediante los datos del presente.
La distribución normal es utilizada comúnmente cuando es relevante considerar:
- Características de forma, figura o configuración de personas, animales, planta, tales como las tallas, pesos, perímetros, etc.
- Particularidades fisiológicas, como pueden ser, los efectos de una misma dosis de un fármaco o de una misma cantidad de abono para las plantas.
- Corregir errores que pueden presentarse al realizar medidas en determinadas magnitudes.
- Elementos escolares como promedios, calificaciones, desempeño, etc.
Todos los tipos de distribución normal se representan en curvas simétricas, cada una de ellas con su respectiva media y desviación estándar.
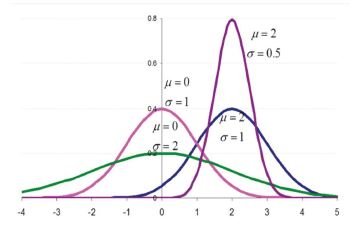
Para poder estudiar este tipo de distribuciones fue creada la distribución normal estandarizada, llamada así por que utiliza las puntuaciones estándar Z, que en el gráfico aparece en color magenta.
La representación gráfica se caracteriza por ser:
- Una distribución simétrica.
- Es asintótica, es decir, sus extremos nunca tocan el eje horizontal, cuyos valores tienden a infinito.
- En el centro de la curva se encuentran la media, la mediana y la moda.
- El área total bajo la curva representa el 100% de los casos.
- Los elementos centrales del modelo son la media y la varianza.
- Debido a que una distribución normal es simétrica, debido a que el eje que pasa por x = μ, deja un área igual a 0.5 de lado izquierda y otro igual a 0.5 a la derecha.
Una variable aleatoria continua, x debe seguir una distribución normal de media μ con valor cero y desviación estañar σ con valor de 1 es decir N (0,1) o N(μ,σ). Dicho en otras palabras, necesitamos conocer la media, y las desviación estándar o la varianza para tener definida la distribución normal.
Para poder utilizar la gráfica tenemos que transformar la variable x que sigue una distribución N (μ,σ) en otra variable Z que siga una distribución N (0, 1). Es decir, utilizaremos la fórmula:
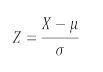

Parámetros (media y desviación estándar)
Los parámetros son conceptualizados como los valores que se calculan para resumir la información recogida en un experimento aleatorio o en las distribuciones de probabilidad.
Como recordarás en tu libro anterior de Probabilidad y Estadística I existen medidas de tendencia central por ejemplo la media, y la moda; así como las de dispersión como la varianza y la desviación estándar; las cuales funcionan como herramientas que ayudan a obtener valores que representan el punto central de los datos, es decir determinar el valor más representativo de la variable que estamos analizando; asimismo nos permiten analizar qué tan cercano o lejano están los datos respecto, por ejemplo, al valor medio.
Para las distribuciones de probabilidad binomial y normal, la media aritmética concurrirá en el centro la distribución; asimismo la desviación estándar será el parámetro de dispersión que nos indique si los datos estudiados están más concentrados o más dispersos, por ejemplo en una campana de Gauss.
Media y desviación estándar en distribuciones binomiales
La media de una distribución binomial es nombrada como valor esperado o esperanza matemática; este es el número de ensayos por la probabilidad de éxito, es decir, el valor que se espera obtener de un experimento estadístico.
La desviación estándar como recordarás es una medida de dispersión para variables; se integra mediante un conjunto de datos que se traducen como una medida de dispersión y nos ayuda a indicar cuánto puede dejarse los valores respecto al promedio (media), por tanto es útil para buscar probabilidades de que un evento ocurra; en los casos de una distribución binomial se calcula como la raíz cuadrada del número de ensayos por la probabilidad de éxitos por la probabilidad de fracasos.

Media y desviación estándar en distribuciones normal
Como ya sabes, la media es definida como la suma de los valores de cierto número de cantidades divididas entre su número; asimismo que es significativa entre algunas, medidas de tendencia central, puesto que, intervienen en operaciones algebraicas. Por su parte la desviación estándar, también considerada como una de las más importantes en las medidas de dispersión incluye aproximadamente el 68% de los términos de una distribución normal. Por sus propiedades, se utiliza con facilidad en el análisis estadístico.
En los casos de las distribuciones normal estándar, siempre tendrá una media (μ) igual a cero y una desviación estándar (σ) igual a uno.

Sin embargo, la distribución normal que es el resultado de dividir la desviación de un dato con respecto a la media aritmética entre la desviación estándar. También se le denomina variable Z.
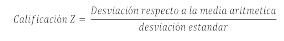

Fuente: Secretaría de Educación Pública. (2015). Probabilidad y estadística I. Ciudad de México.